70 行 Python 代码写春联,行书隶书楷书随你选
前言
相信现在有很多小伙伴都不会写毛笔字了,今天想用python来写一幅春联,不知道有没有人喜欢。该文用的是田英章老师的楷
书,我在网上总共找到了1600个汉字,因此,春联用字被限制在这1600个汉字的小字库中。我个人精力有限,同时受知识产权保
护的限制,不可能制作完整的毛笔字库。那么,能否借用现有的矢量字库,满足朋友们的要求呢?经过一番尝试,发现操作系统
自带的某些矢量字库,是可以作为毛笔字库使用的。以下是简单的演示代码,仅供学习编程技术之用,绝无侵犯字体权利人之权
力的故意,特此声明。
选择矢量字库
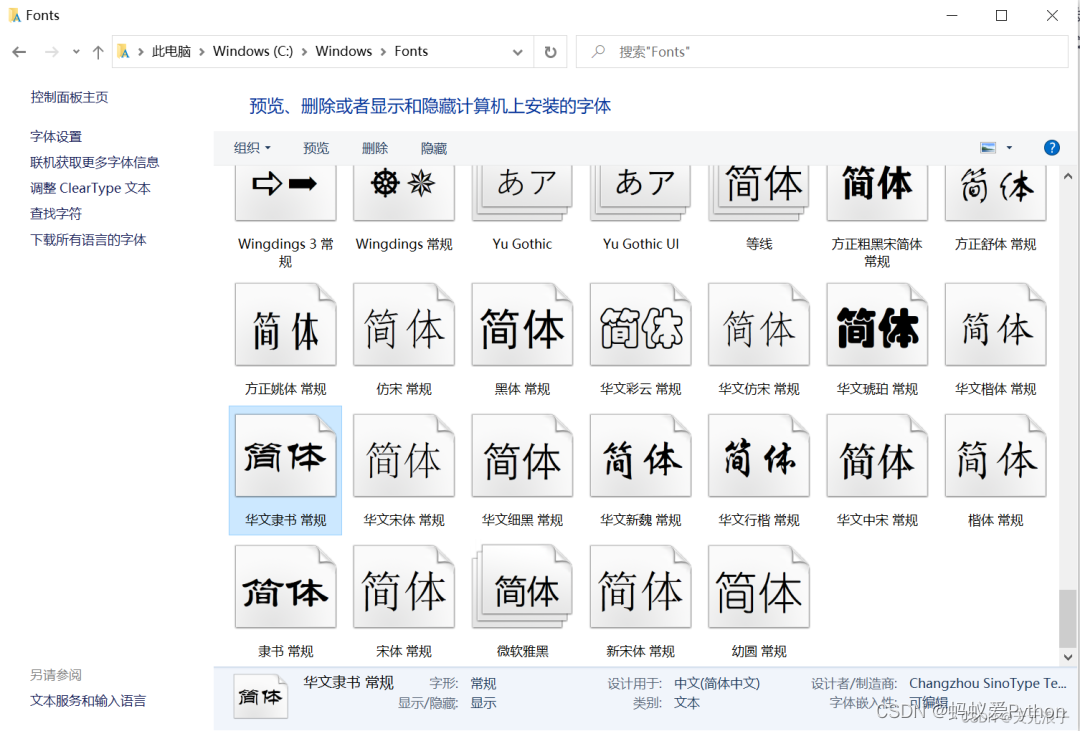
虽然有很多方法可以帮你呈现出系统支持的所有字体文件,我建议最直接的方式是去查看操作系统的字体目录。以Windows为例,我直接在C:\Windows\Fonts这个路径下找到了“华文隶书”这个字库文件,查看属性可知,该文件名为STLITI.TTF。找到了喜欢的字库文件,只需要将其全路径文件名替换到代码中的FONT_FILE常量即可,不需要做其他操作。
选择一款喜欢的春联背景图案
还是以“龙凤呈祥”这个图案为例。如果换用其他的图案,请确保图案是.png格式(背景透明),且是方形的。同字体文件一样,我
们需要将这个背景图案的全路径文件名替换到代码中的BG_FILE常量即可。

完整代码
全部代码总共70余行,使用方法请看注释。
python学习交流Q群:906715085 # ### # -*- coding: utf-8 -*- import os import freetype import numpy as np from PIL import Image
FONT_FILE = r ' C:\Windows\Fonts\STLITI.TTF ' BG_FILE = r ' D:\temp\bg.png ' def text2image(word, font_file, size=128, color= (0,0,0)): """ 使用指定字库将单个汉字转为图像
word - 单个汉字字符串
font_file - 矢量字库文件名
size - 字号,默认128
color - 颜色,默认黑色 """ face = freetype.Face(font_file)
face.set_char_size(size * size)
face.load_char(word)
btm_obj = face.glyph.bitmap
w, h = btm_obj.width, btm_obj.rows
pixels = np.array(btm_obj.buffer, dtype= np.uint8).reshape(h, w)
dx = int(face.glyph.metrics.horiBearingX/64 ) if dx > 0:
patch = np.zeros((pixels.shape[0], dx), dtype= np.uint8)
pixels = np.hstack((patch, pixels))
r = np.ones(pixels.shape) * color[0] * 255 g = np.ones(pixels.shape) * color[1] * 255 b = np.ones(pixels.shape) * color[2] * 255 im = np.dstack((r, g, b, pixels)).astype(np.uint8) return Image.fromarray(im) def write_couplets(text, horv= ' V ' , quality= ' L ' , out_file=None, bg= BG_FILE): """ 写春联
text
- 春联字符串 bg
- - 背景图片路径 horv
- - H-横排,V-竖排 quality
- - 单字分辨率,H-640像素,L-320像素
- out_file - 输出文件名
- """ - size, tsize = (320, 128) if quality == ' L ' else (640, 180 ) - ow, oh = (size, size*len(text)) if horv == ' V ' else (size* len(text), size) - im_out = Image.new( ' RGBA ' , (ow, oh), ' #f0f0f0 ' ) - im_bg = Image.open(BG_FILE) if size < 640 : - im_bg = im_bg.resize((size, size)) - for i, w in enumerate(text): - im_w = text2image(w, FONT_FILE, size=tsize, color= (0,0,0)) - w, h = im_w.size - dw, dh = (size - w)//2, (size - h)//2 - if horv == ' V ' : - im_out.paste(im_bg, (0, i* size)) - im_out.paste(im_w, (dw, i*size+dh), mask= im_w) - else : - im_out.paste(im_bg, (i* size, 0)) - im_out.paste(im_w, (i*size+dw, dh), mask= im_w) - im_out.save( ' %s.png ' %text) os.startfile( ' %s.png ' % text) if __name__ == ' __main__ ' :
write_couplets( ' 普天同庆 ' , horv= ' V ' , quality= ' H ' )
write_couplets( ' 欢度春节 ' , horv= ' V ' , quality= ' H ' )
write_couplets( ' 国泰民安 ' , horv= ' H ' , quality= ' H ' )
样例

最后,祝大家虎年大吉,虎虎生威,身体健康,事事顺心。