【爬虫+情感判定+Top10高频词+词云图】"乌克兰"油管热评python舆情分析
目录
- 一、分析背景
- 二、整体思路
- 三、代码讲解
- 3.1 爬虫采集
- 3.2 情感判定
- 3.3 Top10高频词
- 3.4 词云图
- 四、得出结论
- 五、同步视频演示
- 六、附完整源码
一、分析背景
乌克兰局势这两天日益紧张,任何战争到最后伤害的都是无辜平民,所以没有真正的赢家!
祈祷战争早日结束,世界和平!
油管上讨论乌克兰局势的评论声音不断,采用python的文本情感分析技术,挖掘网友舆论导向。
二、整体思路
选取5个近期”乌克兰“相关视频,分析每个视频下的Top300热评:
- 爬虫采集评论(requests)
- 情感分类打分、打标判定结果(积极/中性/消极)(中文用SnowNLP,英文用TextBlob)
- 统计出Top10高频词(jieba.analyse)
- 绘制词云图(wordcloud)
三、代码讲解
3.1 爬虫采集
爬虫程序依然采用上次爬取李子柒油管评论的程序,在此不再赘述。
封装下爬虫程序,达到采集多个视频评论的目的:
video_id_list = ['pYLjb7xIbOk', 'HnFnyNEuCUk', 'F0lYqJmGf-M', 't51ebUWe0Ag', '0RiEMEpKqic']
def download_comments(video_id_list):
"""
下载视频评论
:param video_id_list: 视频id列表
:return: None
"""
cnt = 1
for id in video_id_list:
print('正在爬取第{}个视频的评论'.format(cnt))
cmd = r"python downloader.py -y={} -o={}.json -s 0 -l 300".format(id, id) # 按热门排序,爬取前300条评论
print('开始爬取:{}'.format(id))
a = os.system(cmd) # 执行爬取评论命令
print('结束爬取:{}'.format(id))
cnt += 1
print('爬取完成:{}'.format(id)) 这样,就把5个代表性视频的前300条热门评论爬取到了,爬取下来是json文件,转换为excel文件:
# 把json批量转换为excel
for file in os.listdir('./'):
if file.endswith('json'):
print(file)
f_head, f_tail = file.split(".")
print(f_head, " || ", f_tail)
try:
df = pd.read_json(file, lines=True)
df.to_excel('{}.xlsx'.format(f_head), index=False, engine='xlsxwriter', encoding='UTF-8')
except Exception as e:
print('Excepted-》{}: {}'.format(file, str(e))) 查看下评论数据的excel文件: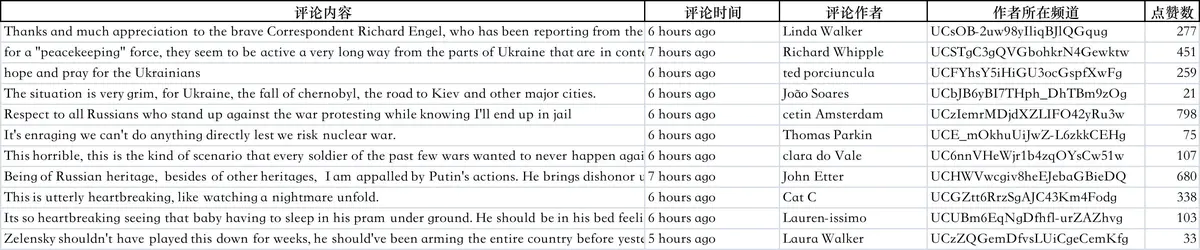
3.2 情感判定
针对每条评论数据,打情感分,判定情感结果,核心逻辑代码:
if not is_chinese(comment): # 不是中文,是英文评论
judge = TextBlob(comment)
sentiments_score = judge.sentiment.polarity
if sentiments_score < 0:
tag = '消极'
elif sentiments_score == 0:
tag = '中性'
else:
tag = '积极'
else: # 是中文评论
sentiments_score = SnowNLP(comment).sentiments
if sentiments_score < 0.5:
tag = '消极'
else:
tag = '积极' 情感得分、判定结果: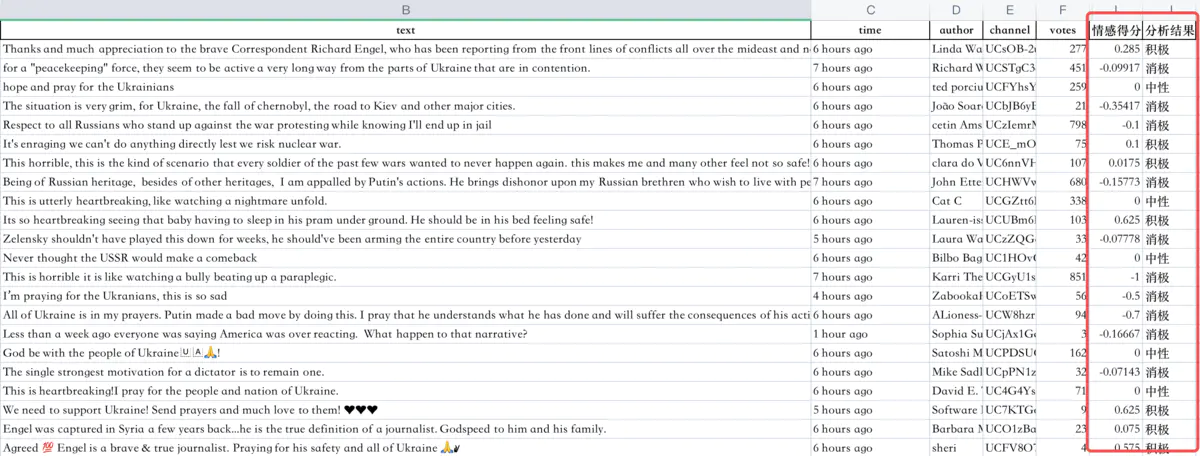
当然,还可以统计出积极、中性、消极各占多少百分比,画出饼图,对分析结果更具有说服力。
3.3 Top10高频词
用jieba自带的统计功能,直接获取到高频词和权重,就不要自己造轮子了!
# 用jieba分词统计评论内容的前10关键词
keywords_top10 = jieba.analyse.extract_tags(v_cmt_str, withWeight=True, topK=10) topK参数传入几,就是统计前几名。
以topK=10为例,统计结果: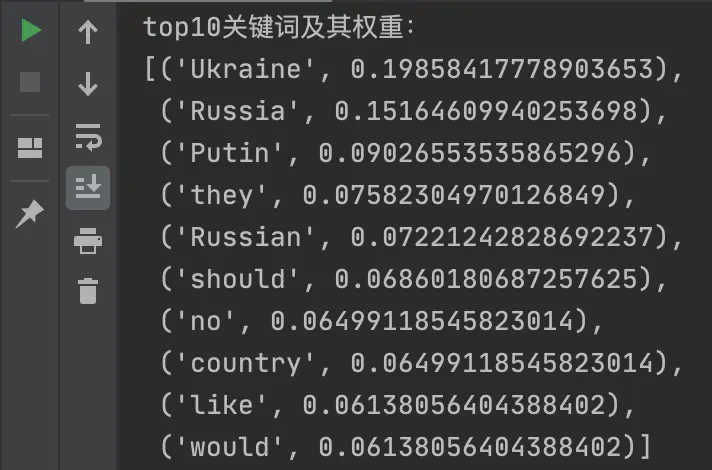
3.4 词云图
采用wordcloud库绘制词云图,词云图也是一种体现高频词的统计方式。
def make_wordcloud(v_str, v_stopwords, v_outfile):
"""
绘制词云图
:param v_str: 输入字符串
:param v_stopwords: 停用词
:param v_outfile: 输出文件
:return: None
"""
print('开始生成词云图:{}'.format(v_outfile))
try:
stopwords = v_stopwords # 停用词
backgroud_Image = plt.imread('乌克兰地图.jpg') # 读取背景图片
wc = WordCloud(
scale=4, # 清晰度
background_color="white", # 背景颜色
max_words=1500, # 最大词数
width=1500, # 图宽
height=1200, # 图高
font_path='/System/Library/Fonts/SimHei.ttf', # 字体文件路径,根据实际情况(Mac)替换
# font_path="C:\Windows\Fonts\simhei.ttf", # 字体文件路径,根据实际情况(Windows)替换
stopwords=stopwords, # 停用词
mask=backgroud_Image, # 背景图片
)
wc.generate(v_str) # 生成词云图
wc.to_file(v_outfile) # 保存图片文件
print('词云文件保存成功:{}'.format(v_outfile))
except Exception as e:
print('make_wordcloud except: {}'.format(str(e))) wordcloud的核心参数说明,我已经加到注释上了↑,请查阅。
采用乌克兰地图作为背景图,最终效果如下:(左:背景图,右:词云图)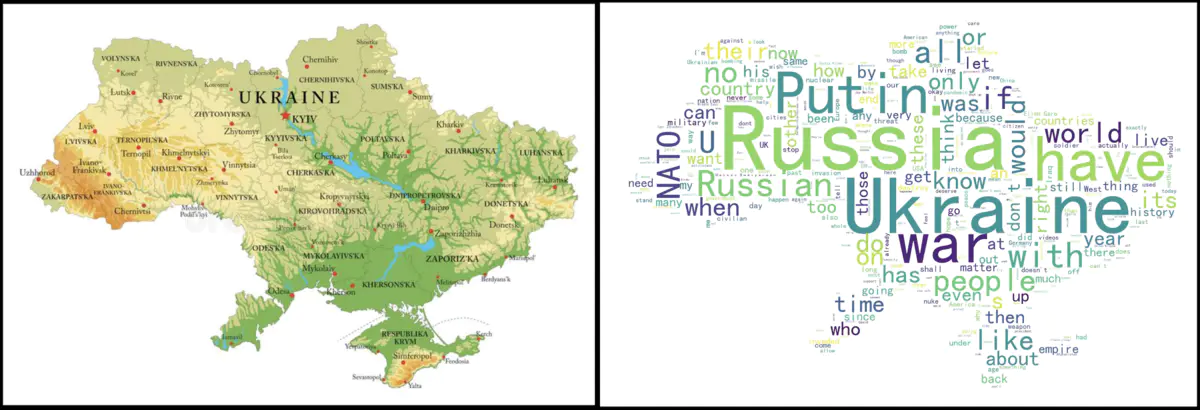
四、得出结论
从情感判定、高频词统计还有词云图体现,网友对此次事件消极和中性的情绪占据了一大部分。
而且仔细查看积极面的评论里,很多评论都是为乌克兰等人民祈福保佑的内容,所以也不是针对战争的积极评价。
所以,整体而言,是负面评价较多。
五、同步视频演示
https://www.zhihu.com/zvideo/1480526739331387392
六、附完整源码
附完整源码:点击这里完整源码
更多源码案例 -> 马哥python说