Python_numpy函数入门
一、什么是numpy?
NumPy(Numerical Python)是Python的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list structure)结构要高效的多(该结构也可以用来表示矩阵(matrix)),支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
终极目的:读取文件数字数据进行处理
NumPy 是一个运行速度非常快的数学库,主要用于数组计算,包含:
1. 一个强大的N维数组对象 ndarray
2. 广播功能函数
3. 整合 C/C++/Fortran 代码的工具
4. 线性代数、傅里叶变换、随机数生成等功能
二、安装numpy(Windows版)
-
首先,第一步打开电脑的运行,快捷键是win+r,然后输入cmd打开命令窗口。
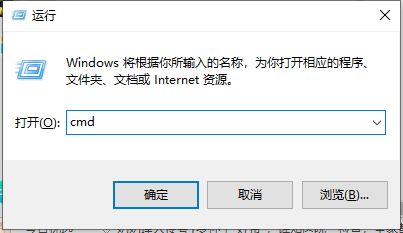
-
第二步,在打开的命令窗口中输入pip --version,查看电脑是否有安装pip(如果有输出版本号即已经安装好,若出现pip不是内部或外部命令则说明没有安装好),注意'--'前面有空格。
-
第三步,如果发现自己没有安装pip,就在命令窗口中输入'easy_install.exe pip'这条命令进行下载。
-
第四步,如果发现自己已经安装pip,但是版本是旧版本的话,可以输入pip install pip --upgrade这条命令,以此来升级pip。
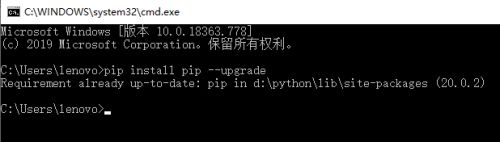
-
第五步,这时候可以重新输入pip --version这条命令,来查看自己的版本。
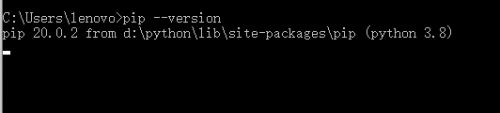
三、NumPy Ndarray 对象
NumPy 最重要的一个特点是其 N 维数组对象 ndarray,它是一系列同类型数据的集合,以 0 下标为开始进行集合中元素的索引。
ndarray 对象是用于存放同类型元素的多维数组。
ndarray 中的每个元素在内存中都有相同存储大小的区域。
ndarray 内部由以下内容组成:
一个指向数据(内存或内存映射文件中的一块数据)的指针。
数据类型或 dtype,描述在数组中的固定大小值的格子。
一个表示数组形状(shape)的元组,表示各维度大小的元组。
一个跨度元组(stride),其中的整数指的是为了前进到当前维度下一个元素需要"跨过"的字节数。
ndarray 的内部结构 :
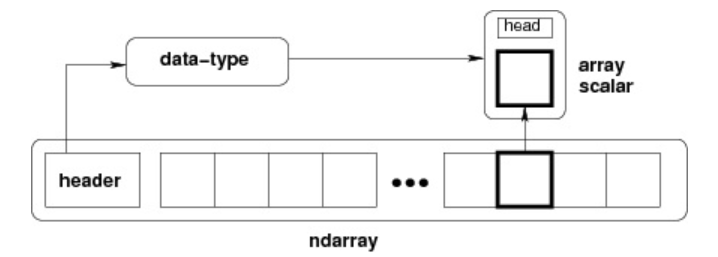
跨度可以是负数,这样会使数组在内存中后向移动,切片中 obj[::-1] 或 obj[:,::-1] 就是如此。
创建一个 ndarray 只需调用 NumPy 的 array 函数即可:
1 numpy.array( object , dtype = None, copy = True, order = None, subok = False, ndmin = 0) 参数说明:
| 名称 | 描述 |
|---|---|
| object | 数组或嵌套的数列 |
| dtype | 数组元素的数据类型,可选 |
| copy | 对象是否需要复制,可选 |
| order | 创建数组的样式,C为行方向,F为列方向,A为任意方向(默认) |
| subok | 默认返回一个与基类类型一致的数组 |
| ndmin | 指定生成数组的最小维度 |
案例:
1 import numpy as np # 给函数取别名方便调用 2 a = np.array([1,2,3 ]) 3 print (a) 4 # 输出结果如下:[1 2 3] 5 6 # 实例 2 7 # 多于一个维度 8 a = np.array([[1, 2], [3, 4 ]]) 9 print (a) 10 # 输出结果如下: 11 # [[1 2] 12 # [3 4]] 13 14 # 实例 3 15 # 最小维度 16 a = np.array([1, 2, 3, 4, 5], ndmin = 2 ) 17 print (a) 18 # 输出如下:[[1 2 3 4 5]] 19 20 # 实例 4 21 # dtype 参数 22 a = np.array([1, 2, 3], dtype = complex) 23 print (a) 24 # 输出结果如下:[1.+0.j 2.+0.j 3.+0.j]
四、NumPy 数据类型
numpy 支持的数据类型比 Python 内置的类型要多很多,基本上可以和 C 语言的数据类型对应上,其中部分类型对应为 Python 内置的类型。下表列举了常用 NumPy 基本类型。
| 名称 | 描述 |
|---|---|
| bool_ | 布尔型数据类型(True 或者 False) |
| int_ | 默认的整数类型(类似于 C 语言中的 long,int32 或 int64) |
| intc | 与 C 的 int 类型一样,一般是 int32 或 int 64 |
| intp | 用于索引的整数类型(类似于 C 的 ssize_t,一般情况下仍然是 int32 或 int64) |
| int8 | 字节(-128 to 127) |
| int16 | 整数(-32768 to 32767) |
| int32 | 整数(-2147483648 to 2147483647) |
| int64 | 整数(-9223372036854775808 to 9223372036854775807) |
| uint8 | 无符号整数(0 to 255) |
| uint16 | 无符号整数(0 to 65535) |
| uint32 | 无符号整数(0 to 4294967295) |
| uint64 | 无符号整数(0 to 18446744073709551615) |
| float_ | float64 类型的简写 |
| float16 | 半精度浮点数,包括:1 个符号位,5 个指数位,10 个尾数位 |
| float32 | 单精度浮点数,包括:1 个符号位,8 个指数位,23 个尾数位 |
| float64 | 双精度浮点数,包括:1 个符号位,11 个指数位,52 个尾数位 |
| complex_ | complex128 类型的简写,即 128 位复数 |
| complex64 | 复数,表示双 32 位浮点数(实数部分和虚数部分) |
| complex128 | 复数,表示双 64 位浮点数(实数部分和虚数部分) |
numpy 的数值类型实际上是 dtype 对象的实例,并对应唯一的字符,包括 np.bool_,np.int32,np.float32,等等。
数据类型对象 (dtype)
数据类型对象(numpy.dtype 类的实例)用来描述与数组对应的内存区域是如何使用,它描述了数据的以下几个方面::
- 数据的类型(整数,浮点数或者 Python 对象)
- 数据的大小(例如, 整数使用多少个字节存储)
- 数据的字节顺序(小端法或大端法)
- 在结构化类型的情况下,字段的名称、每个字段的数据类型和每个字段所取的内存块的部分
- 如果数据类型是子数组,那么它的形状和数据类型是什么。
字节顺序是通过对数据类型预先设定 < 或 > 来决定的。 < 意味着小端法(最小值存储在最小的地址,即低位组放在最前面)。 > 意味着大端法(最重要的字节存储在最小的地址,即高位组放在最前面)。
dtype 对象是使用以下语法构造的:
numpy . dtype ( object , align , copy ) - object - 要转换为的数据类型对象
- align - 如果为 true,填充字段使其类似 C 的结构体。
- copy - 复制 dtype 对象 ,如果为 false,则是对内置数据类型对象的引用
1 import numpy as np 2 # 使用标量类型 3 dt = np.dtype(np.int32) 4 print (dt) 5 # 输出结果为:int32 6 7 # 实例 2 8 # int8, int16, int32, int64 四种数据类型可以使用字符串 'i1', 'i2','i4','i8' 代替 9 dt = np.dtype( ' i4 ' ) 10 print (dt) 11 # 输出结果为:int32 12 # 实例 3 13 14 15 # 字节顺序标注 16 dt = np.dtype( ' <i4 ' ) 17 print (dt) 18 # 输出结果为:int32 19 20 # 下面实例展示结构化数据类型的使用,类型字段和对应的实际类型将被创建。 21 22 # 实例 4 23 # 首先创建结构化数据类型 24 dt = np.dtype([( ' age ' ,np.int8)]) 25 print (dt) 26 # 输出结果为:[('age', 'i1')] 27 28 # 实例 5 29 # 将数据类型应用于 ndarray 对象 30 dt = np.dtype([( ' age ' ,np.int8)]) 31 a = np.array([(10,),(20,),(30,)], dtype = dt) 32 print (a) 33 # 输出结果为:[(10,) (20,) (30,)] 34 35 # 实例 6 36 # 类型字段名可以用于存取实际的 age 列 37 import numpy as np 38 dt = np.dtype([( ' age ' ,np.int8)]) 39 a = np.array([(10,),(20,),(30,)], dtype = dt) 40 print (a[ ' age ' ]) 41 # 输出结果为:[10 20 30]
import numpy as np # 实例 7 student = np.dtype([( ' name ' , ' S20 ' ), ( ' age ' , ' i1 ' ), ( ' marks ' , ' f4 ' )]) print (student) # 输出结果为:[('name', 'S20'), ('age', 'i1'), ('marks', 'f4')] # 实例 8 student = np.dtype([( ' name ' , ' S20 ' ), ( ' age ' , ' i1 ' ), ( ' marks ' , ' f4 ' )])
a = np.array([( ' abc ' , 21, 50),( ' xyz ' , 18, 75)], dtype = student) print (a) # 输出结果为:[('abc', 21, 50.0), ('xyz', 18, 75.0)]
五、NumPy 数组属性
NumPy 数组的维数称为秩(rank),秩就是轴的数量,即数组的维度,一维数组的秩为 1,二维数组的秩为 2,以此类推。
在 NumPy中,每一个线性的数组称为是一个轴(axis),也就是维度(dimensions)。比如说,二维数组相当于是两个一维数组,其中第一个一维数组中每个元素又是一个一维数组。所以一维数组就是 NumPy 中的轴(axis),第一个轴相当于是底层数组,第二个轴是底层数组里的数组。而轴的数量——秩,就是数组的维数。
很多时候可以声明 axis。axis=0,表示沿着第 0 轴进行操作,即对每一列进行操作;axis=1,表示沿着第1轴进行操作,即对每一行进行操作。
NumPy 的数组中比较重要 ndarray 对象属性有:
| 属性 | 说明 |
|---|---|
| ndarray.ndim | 秩,即轴的数量或维度的数量 |
| ndarray.shape | 数组的维度,对于矩阵,n 行 m 列 |
| ndarray.size | 数组元素的总个数,相当于 .shape 中 n*m 的值 |
| ndarray.dtype | ndarray 对象的元素类型 |
| ndarray.itemsize | ndarray 对象中每个元素的大小,以字节为单位 |
| ndarray.flags | ndarray 对象的内存信息 |
| ndarray.real | ndarray元素的实部 |
| ndarray.imag | ndarray 元素的虚部 |
| ndarray.data | 包含实际数组元素的缓冲区,由于一般通过数组的索引获取元素,所以通常不需要使用这个属性。 |
ndarray.ndim
ndarray.ndim 用于返回数组的维数,等于秩。
import numpy as np
a = np.arange(24 ) print (a.ndim) # a 现只有一个维度 # 现在调整其大小 b = a.reshape(2,4,3) # b 现在拥有三个维度 print (b.ndim) # 输出结果为: # 1 # 3
ndarray.shape
ndarray.shape 表示数组的维度,返回一个元组,这个元组的长度就是维度的数目,即 ndim 属性(秩)。比如,一个二维数组,其维度表示"行数"和"列数"。
ndarray.shape 也可以用于调整数组大小。
1 import numpy as np 2 3 a = np.array([[1,2,3],[4,5,6 ]]) 4 print (a.shape) 5 # 输出结果为: 6 # (2, 3) 7 # 调整数组大小。 8 9 # 实例 10 11 a = np.array([[1,2,3],[4,5,6 ]]) 12 a.shape = (3,2 ) 13 print (a) 14 # 输出结果为: 15 16 # [[1 2] 17 # [3 4] 18 # [5 6]]
NumPy 也提供了 reshape 函数来调整数组大小。
# 实例 import numpy as np
a = np.array([[1,2,3],[4,5,6 ]])
b = a.reshape(3,2 ) print (b) # 输出结果为: # [[1, 2] # [3, 4] # [5, 6]]
六、NumPy 创建数组
darray 数组除了可以使用底层 ndarray 构造器来创建外,也可以通过以下几种方式来创建。
numpy.empty
numpy.empty 方法用来创建一个指定形状(shape)、数据类型(dtype)且未初始化的数组:
numpy . empty ( shape , dtype = float , order = 'C' ) 参数说明:
| 参数 | 描述 |
|---|---|
| shape | 数组形状 |
| dtype | 数据类型,可选 |
| order | 有"C"和"F"两个选项,分别代表,行优先和列优先,在计算机内存中的存储元素的顺序。 |
下面是一个创建空数组的实例:
实例
输出结果为:
[[ 6917529027641081856 5764616291768666155 ] [ 6917529027641081859 - 5764598754299804209 ] [ 4497473538 844429428932120 ]] 注意 − 数组元素为随机值,因为它们未初始化。
numpy.zeros
创建指定大小的数组,数组元素以 0 来填充:
numpy.zeros(shape, dtype = float, order = ' C ' ) 参数说明:
| 参数 | 描述 |
|---|---|
| shape | 数组形状 |
| dtype | 数据类型,可选 |
| order | 'C' 用于 C 的行数组,或者 'F' 用于 FORTRAN 的列数组 |
实例
import numpy as np # 默认为浮点数 x = np.zeros(5 ) print (x) # 设置类型为整数 y = np.zeros((5,), dtype = np.int) print (y) # 自定义类型 z = np.zeros((2,2), dtype = [( ' x ' , ' i4 ' ), ( ' y ' , ' i4 ' )]) print (z)
输出结果为:
[ 0. 0. 0. 0. 0. ] [ 0 0 0 0 0 ] [[( 0 , 0 ) ( 0 , 0 )] [( 0 , 0 ) ( 0 , 0 )]] numpy.ones
创建指定形状的数组,数组元素以 1 来填充:
numpy . ones ( shape , dtype = None , order = 'C' ) 参数说明:
| 参数 | 描述 |
|---|---|
| shape | 数组形状 |
| dtype | 数据类型,可选 |
| order | 'C' 用于 C 的行数组,或者 'F' 用于 FORTRAN 的列数组 |
实例
import numpy as np # 默认为浮点数 x = np.ones(5 ) print (x) # 自定义类型 x = np.ones([2,2], dtype = int) print (x)
输出结果为:
[1. 1. 1. 1. 1 .]
[[ 1 1 ]
[ 1 1]]
NumPy 从已有的数组创建数组
numpy.asarray
numpy.asarray 类似 numpy.array,但 numpy.asarray 参数只有三个,比 numpy.array 少两个。
numpy . asarray ( a , dtype = None , order = None ) 参数说明:
| 参数 | 描述 |
|---|---|
| a | 任意形式的输入参数,可以是,列表, 列表的元组, 元组, 元组的元组, 元组的列表,多维数组 |
| dtype | 数据类型,可选 |
| order | 可选,有"C"和"F"两个选项,分别代表,行优先和列优先,在计算机内存中的存储元素的顺序。 |
实例
将列表转换为 ndarray:
实例
import numpy as np
x = [1,2,3] a = np.asarray(x) print (a)
输出结果为:
[ 1 2 3 ] 将元组转换为 ndarray:
实例
import numpy as np
x = (1,2,3 )
a = np.asarray(x) print (a)
输出结果为:
[ 1 2 3 ] 将元组列表转换为 ndarray:
实例
import numpy as np
x = [(1,2,3),(4,5 )]
a = np.asarray(x) print (a)
输出结果为:
[( 1 , 2 , 3 ) ( 4 , 5 )] 设置了 dtype 参数:
实例
import numpy as np
x = [1,2,3 ]
a = np.asarray(x, dtype = float) print (a)
输出结果为:
[ 1. 2. 3. ] NumPy 从数值范围创建数组
numpy.arange
numpy 包中的使用 arange 函数创建数值范围并返回 ndarray 对象,函数格式如下:
numpy . arange ( start , stop , step , dtype ) 根据 start 与 stop 指定的范围以及 step 设定的步长,生成一个 ndarray。
参数说明:
| 参数 | 描述 |
|---|---|
|
起始值,默认为 |
|
终止值(不包含) |
|
步长,默认为 |
|
返回 |
实例
生成 0 到 5 的数组:
实例
import numpy as np
x = np.arange(5 ) print (x)
输出结果如下:
[ 0 1 2 3 4 ] 设置返回类型位 float:
实例
import numpy as np # 设置了 dtype x = np.arange(5, dtype = float) print (x)
输出结果如下:
[ 0. 1. 2. 3. 4. ] 设置了起始值、终止值及步长:
实例
import numpy as np
x = np.arange(10,20,2 ) print (x)
输出结果如下:
[ 10 12 14 16 18 ]
numpy.linspace
numpy.linspace 函数用于创建一个一维数组,数组是一个等差数列构成的,格式如下:
np . linspace ( start , stop , num = 50 , endpoint = True , retstep = False , dtype = None ) 参数说明:
| 参数 | 描述 |
|---|---|
|
序列的起始值 |
|
序列的终止值,如果 |
|
要生成的等步长的样本数量,默认为 |
|
该值为 |
|
如果为 True 时,生成的数组中会显示间距,反之不显示。 |
|
|
以下实例用到三个参数,设置起始点为 1 ,终止点为 10,数列个数为 10。
实例
import numpy as np
a = np.linspace(1,10,10 ) print (a)
输出结果为:
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. ] numpy.logspace
numpy.logspace 函数用于创建一个于等比数列。格式如下:
np . logspace ( start , stop , num = 50 , endpoint = True , base = 10.0 , dtype = None ) base 参数意思是取对数的时候 log 的下标。
| 参数 | 描述 |
|---|---|
|
序列的起始值为:base ** start |
|
序列的终止值为:base ** stop。如果 |
|
要生成的等步长的样本数量,默认为 |
|
该值为 |
|
对数 log 的底数。 |
|
|
实例
import numpy as np # 默认底数是 10 a = np.logspace(1.0, 2.0, num = 10 ) print (a)
输出结果为:
[ 10. 12.91549665 16.68100537 21.5443469 27.82559402 35.93813664 46.41588834 59.94842503 77.42636827 100. ] 将对数的底数设置为 2 :
实例
import numpy as np
a = np.logspace(0,9,10,base=2 ) print (a)
输出如下:
[ 1. 2. 4. 8. 16. 32. 64. 128. 256. 512. ]
七、numpy对数组的操作
1、NumPy 切片和索引
ndarray对象的内容可以通过索引或切片来访问和修改,与 Python 中 list 的切片操作一样。
ndarray 数组可以基于 0 - n 的下标进行索引,切片对象可以通过内置的 slice 函数,并设置 start, stop 及 step 参数进行,从原数组中切割出一个新数组。
实例
import numpy as np
a = np.arange(10 )
s = slice(2,7,2 ) # 从索引 2 开始到索引 7 停止,间隔为2 print (a[s])
输出结果为:
[ 2 4 6 ] 以上实例中,我们首先通过 arange() 函数创建 ndarray 对象。 然后,分别设置起始,终止和步长的参数为 2,7 和 2。
我们也可以通过冒号分隔切片参数 start:stop:step 来进行切片操作:
实例
import numpy as np
a = np.arange(10 )
b = a[2:7:2 ] # 从索引 2 开始到索引 7 停止,间隔为 2 print (b)
输出结果为:
[ 2 4 6 ] 冒号 : 的解释:如果只放置一个参数,如 [2] ,将返回与该索引相对应的单个元素。如果为 [2:] ,表示从该索引开始以后的所有项都将被提取。如果使用了两个参数,如 [2:7] ,那么则提取两个索引(不包括停止索引)之间的项。
实例
import numpy as np
a = np.arange(10) # [0 1 2 3 4 5 6 7 8 9] b = a[5] print (b)
输出结果为:
5 实例
import numpy as np
a = np.arange(10 ) print (a[2:])
输出结果为:
[ 2 3 4 5 6 7 8 9 ] 实例
import numpy as np
a = np.arange(10) # [0 1 2 3 4 5 6 7 8 9] print (a[2:5])
输出结果为:
[ 2 3 4 ] 多维数组同样适用上述索引提取方法:
实例
import numpy as np
a = np.array([[1,2,3],[3,4,5],[4,5,6 ]]) print (a) # 从某个索引处开始切割 print('从数组索引 a[1:] 处开始切割') print(a[1:])
输出结果为:
[[ 1 2 3 ] [ 3 4 5 ] [ 4 5 6 ]] 从数组索引 a [ 1 :] 处开始切割 [[ 3 4 5 ] [ 4 5 6 ]] 切片还可以包括省略号 …,来使选择元组的长度与数组的维度相同。 如果在行位置使用省略号,它将返回包含行中元素的 ndarray。
实例
import numpy as np
a = np.array([[1,2,3],[3,4,5],[4,5,6 ]]) print (a[...,1 ]) # 第2列元素 print (a[1,...]) # 第2行元素 print (a[...,1:]) # 第2列及剩下的所有元素
输出结果为:
[ 2 4 5 ] [ 3 4 5 ] [[ 2 3 ] [ 4 5 ] [ 5 6 ]] 2、NumPy 广播(Broadcast)
广播(Broadcast)是 numpy 对不同形状(shape)的数组进行数值计算的方式, 对数组的算术运算通常在相应的元素上进行。
如果两个数组 a 和 b 形状相同,即满足 a.shape == b.shape ,那么 a*b 的结果就是 a 与 b 数组对应位相乘。这要求维数相同,且各维度的长度相同。
实例
import numpy as np
a = np.array([1,2,3,4 ])
b = np.array([10,20,30,40 ])
c = a * b print (c)
输出结果为:
[ 10 40 90 160 ] 当运算中的 2 个数组的形状不同时,numpy 将自动触发广播机制。如: