乐高玩具数据分析
一、选题的背景
(1)为什么要选择此选题?
乐高是一个很受欢迎的玩具积木品牌,它们通常是成套出售的,用来制作特定的物品,每一套都包含许多不同形状、大小和颜色的零件。它是一个有趣的数据集合,它包含了多年来集合的综合列表,以及每个集合包含的部分数。提供了许多可供探索的空间,特别是因为“集合”文件包含了集合首次发布的年份。集合的大小是如何随时间变化的?什么颜色与女巫主题有关? 你能不能通过一套积木来预测它的主题? 哪一套中使用最多的部件?什么组合里有最稀有的部件? 乐高玩具的颜色是否会随着时间的推移而改变?
(2)要达到的数据分析目标是什么?
中国大陆市场是乐高最重要的市场之一,2020-2022年乐高在中国大陆新增直营门店数量占全球新增数量的比例超过一半。中国玩具市场规模稳步扩大,乐高在全球玩具市场占有率为68.6%,在大陆市场占有率为42.3%,仍有较大的提升空间,创痛积木玩具同质化严重,乐高积极布局IP类产品,拥有全球顶级IP储备,进一步发掘中国本土IP,国产积木新国潮IP崛起可期。同时乐高布局STEAM教育类赛道,以14款积木、400+课程、4大赛事构建完备的STEAM产品体系;国内STEAM教育品牌 以积木为基础,依托高级机器人与编程课程和产品,存在破局可能,贝尔机器人、乐博乐博、童程童美等品牌率先实现规模布局,全国线下运营门店均超200家。中国大陆是其最重要的市场之一,国内市场占有率仍有提升空间。目前处于二次增长期,在中国大陆本土化加速。门店聚焦一二线城市,偏爱大型商超。我们统计了截至2022年6月28日国内各类乐高门店的 信息,可以看到大多数门店集中于一二线城市,并 且多位于大型商超。随着国内人均可支配收入提高 ,下沉市场仍有广阔发展空间。乐高竞品IP产品全盘点。我们盘点了美高(MEGA)积木(国际市场占有率第二的厂商)以及13家国产积木厂商所拥有的IP产品,并与乐高IP产品进行了对比分 析,几乎涵盖了国内积木市场的全部成熟参与者。
将与儿童的互动放在首位。作为一家积木设计与制造商,产品自带教育属性,产品的设计与制造本身就是其社会影响的一部分。因此乐高可 持续发展报告将与儿童的互动放在第一章,阐述通过产品履行社会职责的事例。积木的环保议题。一方面,积木是一种耐用品;另一方面,传统积木多由塑料制成。乐高已经开始使用生物材料替换塑料,并且对积木包装 进行替换,还通过其母公司不断投资可再生能源企业。对员工和供应商的突出重视。乐高在可持续发展报告中使用了较多篇幅阐述与员工和供应商的互动,这是社会责任的重要内容。

二、大数据分析设计方案
(1)本数据集的数据内容与数据特征分析
三个数据集包含了不同的乐高组合中包含哪些部件的信息,它最初是为了帮助那些已经拥有一些乐高积木套的人弄清楚他们还能用自己的作品制造出什么其他玩具。
(2)数据分析的课程设计方案概述(包括实现思路与技术难点)
Python 就不会在编译阶段做类型匹配检查。
拿使用较多的 matplotlib 为列,整个图像为一个Figure 对象,在 Figure 对象中可以包含一个或多个 Axes对象,每个Axes对象都是一个拥有自己坐标系统的绘图区域。Axes 由 xaxis, yaxis, title, data 构成,xaxis 由坐标轴的线 ,tick以及label构成。
麦肯锡思维中很重要的一条原理叫做金字塔原理,它的核心是层次化思考、逻辑化思考、结构化思考。
金字塔:任何一件事情都有一个中心论点,中心论点可以划分成3~7个分论点,分论点又可以由3~7个论据支撑。层层拓展,这个结构由上至下呈金字塔状。
核心法则:MECE,金字塔原理有一个核心法则MECE,全称 Mutually Exclusive Collectively Exhaustive,论点相互独立,尽可能多的列举。
首先得有一个思考作为开始。这是什么意思?因为金字塔是从上而下,需要有一个中心论点,也就是塔尖。我们可以先提出一个问题,比如此产品的核心功能是某某功能吗?
20%的分析过程决定80%的分析结果,抓住关键因素。
2.SQL分组,聚合,多表join操作,groupby, aggregate,join操作,大数据平台Hadoop,大数据架构,分布式存储,Mysql,hive 拉链表(dp 的状态 active 和 history)
3.第一步应该是认真理解业务数据,可以试着理解去每个特征,观察每个特征,理解它们对结果的影响程度。然后,慢慢研究多个特征组合后,它们对结果的影响。明确各个特征的类型,如果这些数据类型不是算法部分期望的数据类型,你还得想办法编码成想要的。比如常见的数据自增列 id 这类数据,是否有必要放到你的算法模型中,因为这类数字很可能被当作数字读入。某些列的取值类型,虽然已经是数字了,它们的取值大小表示什么含义你也要仔细捉摸。因为,数字的相近相邻,并不一定代表另一种层面的相邻。找出异常数据,统计中国家庭人均收入时,如果源数据里面,有王建林,马云等这种富豪,那么,人均收入的均值就会受到极大的影响,这个时候最好,绘制箱形图,看一看百分位数。处理缺失值, 现实生产环境中,拿到的数据恰好完整无损、没有任何缺失数据的概率,和买彩票中将的概率差不多。 数据缺失的原因太多了,业务系统版本迭代, 之前的某些字段不再使用了,自然它们的取值就变为 null 了;再或者,压根某些数据字段在抽样周期里,就是没有写入数据…… 头疼的数据不均衡问题, 理论和实际总是有差距的,理论上很多算法都存在一个基本假设,即数据分布总是均匀的。这个美好的假设,在实际中,真的存在吗?很可能不是! 算法基于不均衡的数据学习出来的模型,在实际的预测集上,效果往往差于训练集上的效果,这是因为实际数据往往分布得很不均匀,这时候就要考虑怎么解决这些问题。
三、数据分析步骤
(1)数据源
数据集 :Rebrickable | Rebrickable - Build with LEGO
下载地址:LEGO Database 乐高数据库_数据集-阿里云天池 (aliyun.com)
下载sets.csv、themes.csv和colors.csv三个数据集。


(2)在乐高旗舰店,商品标题都有什么特点。可以看到标题中,"积木"、"玩具"、"XX系列"都被常常提到。同时"送礼"、"创意"、"益智"、"收藏"等也常出现。


pandas用.isna()或者.isnull()检查是否存在NaN。

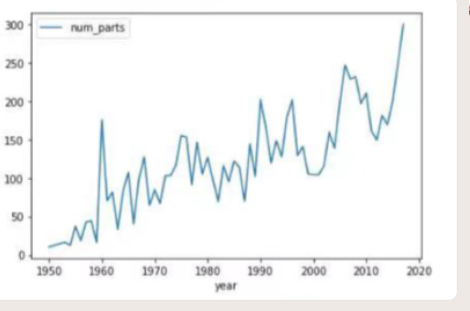
# Explore Lego Sets 探索乐高玩具
%matplotlib inline
#create a summary of avarage number of parts by year:'parts_by_year'
#创建一份按年份列出的零件平均数量的摘要:'parts_by_year'
parts_by_year=df[['year','num_parts']].groupby('year').mean()
#plot trends in average number of parts by year
#按年份绘制零件平均数量的趋势图
parts_by_year.plot()
# Exploring Colors 探索颜色
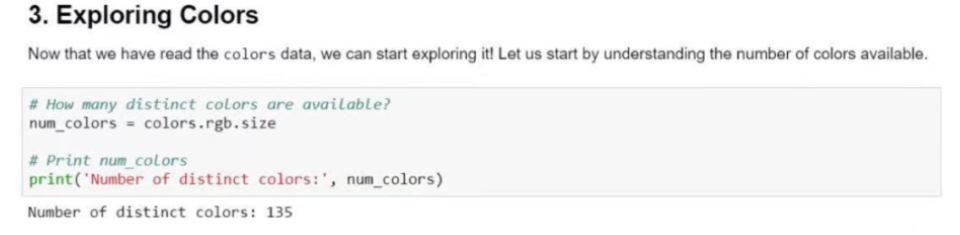
# How many distinct colors are available有多少种不同的颜色可用
num_colors=colors.rgb.size
# print num_colors
#打印
print('Number of distinct colors:',num_colors)
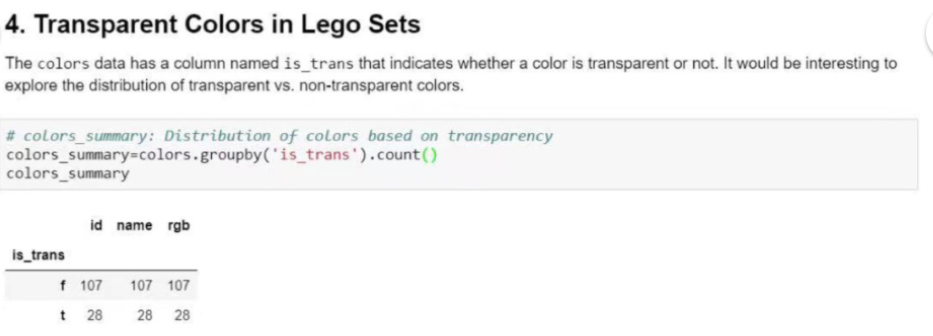
#Transparent Colors in Lego Sets乐高玩具中的透明颜色
colors_summary=colors.groupby('is_trans').count()
colors_summary
评估模型,对测试集进行评估

import stylecloud
from IPython.display import Image
# 绘制词云图
stylecloud.gen_stylecloud(
text=' '.join(text),
collocations=False,
font_path=r"D:\Python\sets.csv"
icon_name='fas fa-plane',
background_color='pink',
size=768,
output_name='词云图.png'
)
Image(filename='词云图.png')



data_pair=[list(z) for z in zip(cut_purchase.index.tolist(),cut_purchase.values.tolist())]
# 绘制饼图
piel=Pie()
piel.add('',data_pair,radius=['35%','60%'])
piel.set_global_opts(title_opts=opts.TitleOpts(title='各个价格商品区间'),
legend_opts=opts.LegendOpts(orient='vertical',pos_top='15%',pos_left='2%'))
piel.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%"))
piel.set_colors(['#EF9050','#3B7BA9','#6FB27C','#FFAF34','#D7BFD7','#00BFFE','#7FFFAA'])
piel.render_notebook()
玩具销量排名分析

(3) 附完整程序源代码
1 # 导入模块包
2 import pandas as pd 3 import numpy as np 4 import matplotlib.pyplot as plt 5 from sklearn import linear_model 6 import seaborn as sns # 显示效果更优化
7 import time 8 import jiebafrom pyecharts.charts 9 import Bar, Line, Pie, Map, Pagefrom pyecharts 10 import options as opts from pyecharts.globals 11 import SymbolType 12 import stylecloud 13 import keras 14 from keras import layers 15 from keras import models 16 from keras.layers import Dense, Dropout, Activation, Flatten 17
18 # #运行配置参数中的字体(font)为黑体(SimHei)
19 matplotlib.rcParams[ ' font.sans-serif ' ] = [ ' SimHei ' ] 20 # 运行配置参数总的轴(axes)正常显示正负号(minus)
21 matplotlib.rcParams[ ' axes.unicode_minus ' ]= False 22 sns.set(font= ' SimHei ' ) 23
24 # 导入sets.csv包
25 df = pd.read_csv(r " D:\python\sets.csv " ) 26 df.head(10 ) 27
28 # 导入themes.csv包
29 themes = pd.read_csv(r " D:\python\themes.csv " ) 30 themes.head(10 ) 31
32 # 导入colors.csv包
33 colors = pd.read_csv(r " D:\python\colors.csv " ) 34 colors.head(10 ) 35
36 # sets.csv的info() 数据集各列的数据类型,是否为空值,内存占用情况
37 df= df.info() 38
39 # themes.info()
40 themes= themes.info() 41
42 # colors.info()
43 colors= colors.info() 44
45 # 去除重复值
46 df.drop_duplicates(inplace= True) 47 df 48
49 # 删除不必要的列 id
50 themes = themes.drop([ ' id ' ],axis=1 ) 51 themes.head(1 ) 52
53 # 对数值型字段进行描述性统计,并查看异常值
54 df.describe() 55
56 # 查看各字段的缺失值数量
57 df.isna().sum() 58
59 # 大数据分析过程
60 # 绘制每个特征的分布
61 df.columns 62
63 # value_counts 直接用来计算Series里面相同数据出现的频率
64 pd.Series(df[ ' name ' ]).value_counts() 65
66 # 读取矩阵的长度
67 df.shape 68
69 # Exploring Colors 探索颜色
70 # How many distinct colors are available有多少种不同的颜色可用
71 num_colors= colors.rgb.size 72
73 # print num_colors
74 # 打印
75 print ( ' Number of distinct colors: ' ,num_colors) 76
77 # Transparent Colors in Lego Sets乐高玩具中的透明颜色
78 colors_summary=colors.groupby( ' is_trans ' ).count() 79 colors_summary 80
81 # Explore Lego Sets 探索乐高玩具
82 % matplotlib inline 83 # create a summary of avarage number of parts by year:'parts_by_year'
84 # 创建一份按年份列出的零件平均数量的摘要:'parts_by_year'
85 parts_by_year=df[[ ' year ' , ' num_parts ' ]].groupby( ' year ' ).mean() 86
87 # plot trends in average number of parts by year
88 # 按年份绘制零件平均数量的趋势图
89 parts_by_year.plot() 90
91 merged[merged[ ' set_num ' ].isnull()].shape 92
93 bar1 = ( 94 Bar(init_opts=opts.InitOpts(theme= ' dark ' , width= ' 1000px ' ,height = ' 500px ' )) 95 .add_xaxis(shopname.index.tolist()) 96 .add_yaxis( "" ,shopname.values.tolist()) 97 .set_series_opts( 98 label_opts= opts.LabelOpts( 99 is_show= True, 100 position= ' insideRight ' , 101 font_style= ' italic '
102 ), 103 itemstyle_opts= opts.ItemStyleOpts( 104 color= JsCode( 105 """ new echarts.graphic.LinearGradient(1, 0, 0, 0, 106 [{offset: 0,color: 'rgb(255,99,71)'}, {offset: 1,color: 'rgb(32,178,170)'}]) """
107 ) 108 ) 109 ) 110 .set_global_opts( 111 title_opts=opts.TitleOpts(title= " 商家上线的商品数目Top20 " ), 112 xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=45 )), 113 legend_opts=opts.LegendOpts(is_show= True)) 114 .reversal_axis() 115 ) 116 bar1.render_notebook() 117
118 bar= ( 119 Bar(init_opts=opts.InitOpts(height= ' 500px ' ,width= ' 1000px ' ,theme= ' dark ' )) 120 .add_xaxis(price_top.index.tolist()) 121 .add_yaxis( 122 ' 单价最高的商品 ' , 123 price_top.values.tolist(), 124 label_opts=opts.LabelOpts(is_show=True,position= ' top ' ), 125 itemstyle_opts= opts.ItemStyleOpts( 126 color=JsCode( """ new echarts.graphic.LinearGradient( 127 0, 0, 0, 1,[{offset: 0,color: 'rgb(255,99,71)'}, {offset: 1,color: 'rgb(32,178,170)'}]) 128 """
129 ) 130 ) 131 ) 132 .set_global_opts( 133 title_opts= opts.TitleOpts( 134 title= ' 单价最高的商品详细柱状图 ' ), 135 xaxis_opts=opts.AxisOpts(name= ' 玩具名称 ' , 136 type_= ' category ' , 137 axislabel_opts=opts.LabelOpts(rotate=90 ), 138 ), 139 yaxis_opts= opts.AxisOpts( 140 name= ' 单价/元 ' , 141 min_= 0, 142 max_=39980.0 , 143 splitline_opts=opts.SplitLineOpts(is_show=True,linestyle_opts=opts.LineStyleOpts(type_= ' dash ' )) 144 ), 145 tooltip_opts=opts.TooltipOpts(trigger= ' axis ' ,axis_pointer_type= ' cross ' ) 146 ) 147
148 .set_series_opts( 149 markline_opts= opts.MarkLineOpts( 150 data= [ 151 opts.MarkLineItem(type_= ' average ' ,name= ' 均值 ' ), 152 opts.MarkLineItem(type_= ' max ' ,name= ' 最大值 ' ), 153 opts.MarkLineItem(type_= ' min ' ,name= ' 最小值 ' ), 154 ] 155 ) 156 ) 157 ) 158 bar.render_notebook() 159
160 def get_cut_words(content_series): 161 stop_words= [] 162 with open( " D:\Python\sets.csv " , ' r ' ,encoding= ' utf-8 ' )as f: 163 lines= f.readlines() 164 for line in lines: 165 stop_words.append(line.strip()) 166 # 添加关键词
167 my_words=[ ' 乐高 ' , ' 悟空 ' , ' 大颗粒 ' , ' 小颗粒 ' ] 168 for i in my_words: 169 jieba.add_word(i) 170 # 自定义停用词
171 # my_stop_words=[]
172 # stop_words.extend(my_stop_words)
173
174 # 分词
175 word_num=jieba.lcut(content_series.str.cat(sep= ' 。 ' ),cut_all= False) 176 # 条件筛选
177 word_num_selected=[i for i in word_num if i not in stop_words and len(i)>=2 ] 178 return word_num_selected 179 text=get_cut_words(content_series=df_tb[ ' goods_name ' ]) 180 text[:10 ] 181
182 import stylecloud 183 from IPython.display import Image 184 # 绘制词云图
185 stylecloud.gen_stylecloud( 186 text= ' ' .join(text), 187 collocations= False, 188 font_path=r ' F:Python数据分析课程python数据处理Pandas练习数据分析项目练习legao3225simhei.ttf ' , 189 icon_name= ' fas fa-plane ' , 190 background_color= ' pink ' , 191 size=768 , 192 output_name= ' 词云图.png '
193 ) 194 Image(filename= ' 词云图.png ' ) 195
196 data_pair=[list(z) for z in zip(cut_purchase.index.tolist(),cut_purchase.values.tolist())] 197
198 # 绘制饼图
199 piel= Pie() 200 piel.add( '' ,data_pair,radius=[ ' 35% ' , ' 60% ' ]) 201 piel.set_global_opts(title_opts=opts.TitleOpts(title= ' 不同价格区间的销售额整体表现 ' ), 202 legend_opts=opts.LegendOpts(orient= ' vertical ' ,pos_top= ' 15% ' ,pos_left= ' 2% ' )) 203 piel.set_series_opts(label_opts=opts.LabelOpts(formatter= " {b}:{d}% " )) 204 piel.set_colors([ ' #EF9050 ' , ' #3B7BA9 ' , ' #6FB27C ' , ' #FFAF34 ' , ' #D7BFD7 ' , ' #00BFFE ' , ' #7FFFAA ' ]) 205 piel.render_notebook() 206
207 df[ ' price_cut ' ]= price_cut 208
209 cut_purchase=df.groupby( ' price_cut ' )[ ' sales_volume ' ].sum() 210 cut_purchase 211
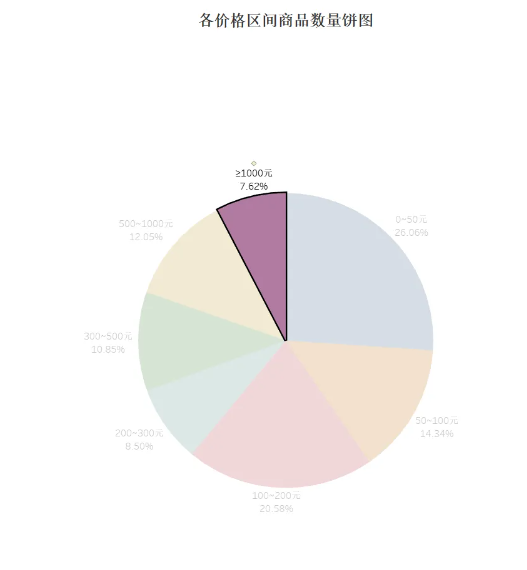
212 bar3= Bar() 213 bar3.add_xaxis([ ' 0~50元 ' , ' 50~100 ' , ' 100~200元 ' , ' 200~300元 ' , ' 300~500元 ' , ' 500~1000元 ' , ' 1000元以上 ' ]) 214 bar3.add_yaxis( '' ,[895,486,701,288,370,411,260 ]) 215 bar3.set_global_opts(title_opts=opts.TitleOpts(title= ' 不同价格区间的商品数量 ' ), 216 visualmap_opts=opts.VisualMapOpts(max_=900 )) 217 bar3.render_notebook() 218
219 # 国内各省份乐高销量
220 province_num=df_tb.groupby( ' province ' )[ ' purchase_num ' ].sum().sort_values(ascending= False) 221
222 province_num[:10 ] 223
224 map1= Map() 225 map1.add( "" ,[list(z) for z in zip(province_num.index.tolist(),province_num.values.tolist())], 226 maptype= ' china ' ) 227 map1.set_global_opts( 228 title_opts=opts.TitleOpts(title= ' 国内各产地乐高销量分布图 ' ), 229 visualmap_opts=opts.VisualMapOpts(max_=172277 ) 230 ) 231 map1.render_notebook() 232
233 province_top10=df_tb.province.value_counts()[:10 ] 234 province_top10 235 # image-20201013210440405
236
237 bar2= Bar() 238 bar2.add_xaxis(province_top10.index.tolist()) 239 bar2.add_yaxis( '' ,province_top10.values.tolist()) 240 bar2.set_global_opts( 241 title_opts=opts.VisualMapOpts(max_=1000 ) 242 ) 243 bar2.render_notebook() 244
245 # 对商品店铺名称进行分组,并对购买数量进行求和,降序排序,取前10条数据
246 shop_top10=df_tb.groupby( ' shop_name ' )[ ' purchase_num ' ].sum().sort_values(ascending=False).head(10 ) 247 shop_top10 248
249 条形图 250 # bar1=Bar(init_opts=opts.InitOpts(width='1350px',height='750px'))
251 bar1= Bar() 252 bar1.add_xaxis(shop_top10.index.tolist()) 253 bar1.add_yaxis( '' ,shop_top10.values.tolist()) 254 bar1.set_global_opts(title_opts=opts.TitleOpts(title= ' 乐高销量排名Top10淘宝店铺 ' ), 255 xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15 )), 256 visualmap_opts=opts.VisualMapOpts(max_=28669 ) 257 ) 258 bar1.render_notebook() 259
260 # 店铺销量前十可视化
261 # 提取数据
262 shop_top10 = data.groupby( ' 店铺名称 ' ,as_index=False).sum().sort_values(by= ' 销量 ' , ascending=False).head(10).reset_index(drop= True) 263 # 绘图
264 plt.figure(figsize=(15,8 )) 265 pic = sns.barplot(x= ' 店铺名称 ' , y= ' 销量 ' , data=shop_top10,palette= " summer_r " ) 266 for a,b in zip(shop_top10.index, shop_top10[ ' 销量 ' ]): 267 pic.text(a,b,b,ha= ' center ' , va= ' bottom ' ) 268 plt.xticks(rotation=45 ) 269 plt.title( " 店铺销量前十 " ,fontsize=18, pad=20 ) 270
271 # 排名前十的省份可视化
272 province_top10 = pd.DataFrame((data.省份.value_counts()[:10])).reset_index().rename(columns={ " index " : " 地区 " , " 省份 " : " 数量 " }) 273 plt.figure(figsize=(15,8 )) 274 pic = sns.barplot(x= ' 地区 ' , y= ' 数量 ' , data=province_top10,palette= " spring_r " ) 275 for a,b in zip(province_top10.index, province_top10[ ' 数量 ' ]): 276 pic.text(a,b,b,ha= ' center ' , va= ' bottom