python实战-解析swagger-api接口信息
# _*_ coding: UTF-8 _*_
"""
@project -> file : city-test -> swagger_api_parse_backup
@Author : qinmin.vendor
@Date : 2023/1/12 17:55
@Desc :
"""
import copy
import json
import os.path
import sys
from utils.operation_datas import operationExcle
from utils.request_main import requestMain
from utils.data_util import dataUtil
#将汉字转换拼音: https://blog.csdn.net/weixin_42464956/article/details/110927073
from xpinyin import Pinyin
from utils.wrapper_util import exec_time_wrapper
class swaggerApiParse():
excel_path='./'
url='swagger api url'
excle_name=f'maint-api{"-".join(url.split("/")[3:])}.xlsx'
requst=requestMain()
_data=dataUtil()
_pinyin=Pinyin()
api_data=requst.get_main(url=url,data=None,headers=None).json()
api = api_data['paths'] # 取swagger文件内容中的path,文件中path是键名
api_uri_list = [] # 创建接口地址空列表
api_method_list = [] # 创建请求方式空列表
api_name_list = [] # 创建接口描述空列表
api_params_path_list = []
api_params_path_list_descs = []
api_params_body_list = []
api_params_body_list_descs = []
# 定义响应相关内容
api_response_key='200'
api_response_body_list = []
api_response_body_list_descs = []
api_uri=""
# 定义接口参数描述中各个类型的默认值
api_params_ref_result_properties_type_default={
"int":0,"integer":0, "number":0,"float":0.0,"double":0.0,
"null":None,"object":dict(),"set":set(),"string":"","array":[],
"bool":False,"boolean":False,
}
@classmethod
def get_info_info(cls):
'''解析api数据'''
def dispose_api_params_desc_result(api_params,api_params_ref_result,api_data):
'''处理请求参数中的key,转为jsonpath提取数据并返回'''
def replece_key(api_params_ref_json_path,api_data,split_symbol='.'):
'''处理引用为标准的jsonpath,并替换原dict key'''
if api_params_ref_json_path.startswith('$.'):
api_params_ref_json_path_split = api_params_ref_json_path.split(split_symbol)
if api_params_ref_json_path_split[1] in api_data.keys():
keys=list(api_data[api_params_ref_json_path_split[1]].keys())
if api_params_ref_json_path_split[2] in keys:
target_no_special_key=api_params_ref_json_path_split[2].replace("«", "").replace("»","").replace(',','')
if " " in api_params_ref_json_path_split[2]:
target_no_special_key=target_no_special_key.split(" ")[0]
if cls._data.is_contains_chinese(api_params_ref_json_path_split[2]):
result = cls._pinyin.get_pinyin(api_params_ref_json_path_split[2])
result = result.replace('-', '') if result else result
api_data[api_params_ref_json_path_split[1]][result]=api_data[api_params_ref_json_path_split[1]][api_params_ref_json_path_split[2]]
api_params_ref_json_path_split[2]=result
## 定义去除特殊字符后的目标key
if not api_data[api_params_ref_json_path_split[1]].\
get(target_no_special_key):
api_data[api_params_ref_json_path_split[1]][target_no_special_key] = \
api_data[api_params_ref_json_path_split[1]][api_params_ref_json_path_split[2]]
del api_data[api_params_ref_json_path_split[1]][api_params_ref_json_path_split[2]]
return api_data
api_params_ref_is_array=False #标识接口参数是否为array
if not api_params:
return "描述key为空",api_params_ref_result,api_params_ref_is_array
'''解析请求参数为json数据的接口'''
api_params_ref = api_params
# params专用
if api_params.get("schema"):
if api_params.get("schema").get("$ref"):
api_params_ref=api_params['schema']['$ref']
# response专用
elif api_params.get("data"):
if api_params.get("data").get("$ref"):
api_params_ref=api_params['data']['$ref']
elif api_params.get("$ref"):
api_params_ref = api_params['$ref']
# '''解析请求参数格式为非json的数据,例如:array[object]'''
if not str(api_params_ref).startswith('#'):
# print("api_params_ref:",api_params_ref)
api_params_ref_type = {}
if api_params.get("schema"):
if api_params.get("schema").get("type"):
api_params_ref_type = api_params['schema']['type']
elif api_params.get("data"):
if api_params.get("data").get("type"):
api_params_ref_type = api_params['data']['type']
if api_params_ref_type:
if api_params_ref_type in cls.api_params_ref_result_properties_type_default.keys():
api_params_ref = api_params['schema']['items']['$ref'] if api_params.get(
'schema') and api_params.get('schema').get('items') and \
api_params.get('schema').get('items').get('$ref') else api_params
if api_params_ref_type == 'array':
api_params_ref_is_array = True
else:
api_params_ref_type = api_params['type'] if api_params.get('type') and api_params.get(
'items') else {}
if api_params_ref_type:
if api_params_ref_type in cls.api_params_ref_result_properties_type_default.keys():
api_params_ref = api_params['items']['$ref'] if api_params.get(
'items') and api_params.get('items').get('$ref') else api_params
if api_params_ref_type == 'array':
api_params_ref_is_array = True
api_params_ref_json_path = str(api_params_ref).replace('#', '$').replace('/', '.')
if " " in api_params_ref_json_path:
api_data=replece_key(api_params_ref_json_path=api_params_ref_json_path,api_data=api_data)
api_params_ref_json_path_all = api_params_ref_json_path.split(' ')
api_params_ref_json_path = api_params_ref_json_path_all[0]
elif "«" in api_params_ref_json_path or "»" in api_params_ref_json_path:
api_data=replece_key(api_params_ref_json_path=api_params_ref_json_path,api_data=api_data)
api_params_ref_json_path=api_params_ref_json_path.replace("«","").replace("»","").replace(',','')
api_params_ref_json_path_is_contains_chinese=cls._data.is_contains_chinese(api_params_ref_json_path)
if api_params_ref_json_path_is_contains_chinese:
api_data=replece_key(api_params_ref_json_path=api_params_ref_json_path,api_data=api_data)
api_params_ref_json_path = cls._pinyin.get_pinyin(api_params_ref_json_path)
api_params_ref_json_path = api_params_ref_json_path.replace('-', '') if api_params_ref_json_path else api_params_ref_json_path
if api_params_ref_json_path.startswith("$."):
api_params_ref_result = cls._data.json_path_parse_public(json_obj=api_data, json_path=api_params_ref_json_path)
api_params_ref_result = api_params_ref_result[0] if api_params_ref_result and len(api_params_ref_result)==1 else api_params_ref_result
return api_params_ref,api_params_ref_result,api_params_ref_is_array
def api_params_desc_convert_to_params(api_params_ref_result:dict,api_data:dict):
'''将接口示例对象转换为可用的请求参数'''
def recursion_get_api_child_parms(properties_key, api_params_ref_result):
'''递归解析子节点参数信息'''
api_params_ref, api_params_ref_result, api_params_ref_is_array = dispose_api_params_desc_result(
api_params=api_params_ref_result_properties[i],
api_params_ref_result=api_params_ref_result, api_data=api_data)
# api_params_ref没有#时,代表不再有json参数嵌套,不在调用
if str(api_params_ref).startswith("#/"):
api_params = api_params_desc_convert_to_params(api_params_ref_result=api_params_ref_result,
api_data=cls.api_data)
properties_child_dict = {properties_key: api_params}
return api_params_ref_is_array,properties_child_dict
return False,{}
_api_params_ref_result_properties_dict = dict()
if (not api_params_ref_result) or isinstance(api_params_ref_result,str) :
return _api_params_ref_result_properties_dict
api_params_ref_result_format=api_params_ref_result['type'] if api_params_ref_result.get('type') else api_params_ref_result
if api_params_ref_result_format=='object':
api_params_ref_result_properties=api_params_ref_result['properties'] if api_params_ref_result.get('properties') else {}
for i in api_params_ref_result_properties:
# print("api_params_ref_result_properties[i]:",api_params_ref_result_properties[i])
if isinstance(api_params_ref_result_properties[i],dict) and \
(api_params_ref_result_properties[i].get('items')
and api_params_ref_result_properties[i].get('items').get("$ref") ) \
or api_params_ref_result_properties[i].get("$ref")\
or (api_params_ref_result_properties[i].get("schema") and api_params_ref_result_properties[i].get("schema").get('$ref')):
# print("开始递归处理")
api_params_ref_is_array,properties_child_dict=recursion_get_api_child_parms(properties_key=i,api_params_ref_result=api_params_ref_result)
if api_params_ref_is_array:
for cd in properties_child_dict:
if not isinstance(properties_child_dict[cd],(list,tuple,set)):
properties_child_dict[cd]=[properties_child_dict[cd]]
_api_params_ref_result_properties_dict.update(properties_child_dict)
else:
api_params_ref_result_properties_type=api_params_ref_result_properties[i]['type'] if \
api_params_ref_result_properties[i].get('type') else 'string'
# 如果存在参数示例,则使用参数示例代替定义的默认值
api_params_ref_result_properties_example=api_params_ref_result_properties[i]['example'] if \
api_params_ref_result_properties[i].get('example') else None
if api_params_ref_result_properties_example:
if isinstance(api_params_ref_result_properties_example, str):
api_params_ref_result_properties_example = api_params_ref_result_properties_example.replace(
'"', '').replace("'", '').replace(' ','')
if api_params_ref_result_properties_example.startswith('[') and api_params_ref_result_properties_example.endswith(']'):
api_params_ref_result_properties_example=api_params_ref_result_properties_example[1:-1].split(',')
# print("api_params_ref_result_properties_example:",api_params_ref_result_properties_example)
_api_params_ref_result_properties_dict[i]=api_params_ref_result_properties_example
else:
_api_params_ref_result_properties_dict[i]=\
cls.api_params_ref_result_properties_type_default[api_params_ref_result_properties_type]
# print(_api_params_ref_result_properties_dict)
return _api_params_ref_result_properties_dict
def dispost_output_api_params(api_params,api_params_type,api_params_ref_result):
'''api_params_type跟据输出最终需要的api_params'''
if not api_params:
return "描述key为空",[],{}
__api_params=copy.deepcopy(api_params)
if api_params_type!='response':
api_params=[i for i in api_params if api_params_type in i.values()]
if api_params_type in ('body','response'):
if api_params:
if isinstance(api_params,list):
api_params=api_params[0]
else:
api_params=api_params
else:
api_params={}
'''处理body参数'''
api_params_ref,api_params_ref_result,api_params_ref_is_array=dispose_api_params_desc_result(
api_params=api_params,api_params_ref_result=api_params_ref_result,api_data=cls.api_data)
# #将api参数转换为最终需要的格式
api_params_out=api_params_desc_convert_to_params(api_params_ref_result=api_params_ref_result,api_data=cls.api_data)
if api_params_ref_is_array and ( not isinstance(api_params_out,(list,tuple))):
api_params_out=[api_params_out]
return api_params_ref,api_params_ref_result,api_params_out
elif api_params_type in ('path','query'):
'''处理path参数'''
api_params_ref="参数为path的请求没有描述key(不存在外部引用)"
if not api_params:
if api_params_type=='path':
api_params_type='query'm
elif api_params_type=='query':
api_params_type='path'
api_params = [i for i in __api_params if api_params_type in i.values()]
api_params_ref_result=api_params
api_params_out=dict()
for api_param_dict in api_params:
params_type=api_param_dict['type'] if api_param_dict.get('type') else 'string'
params_filed=api_param_dict['name'] if api_param_dict.get('name') else None
if params_filed :
api_params_out[params_filed]=cls.api_params_ref_result_properties_type_default[params_type]
return api_params_ref,api_params_ref_result,api_params_out
for path in cls.api.keys(): # 循环取key
values = cls.api[path] # 根据key获取值
cls.api_uri=path
api_params_ref_result = "描述结果为空" # 保存请求示例中的额外嵌套的信息
api_response_ref_result = "响应结果为空" # 保存请求示例中的额外嵌套的信息
# if path=='/v1/collector/find-aggregate':
for i in values.keys():
cls.api_uri_list.append(path) # 将path写入接口地址列表中
api_method = i # 获取请求方式,文件中请求方式是key
cls.api_method_list.append(api_method) # 将method写入请求方式列表中
tags = values[api_method]['tags'][0] # 获取接口分类
# # 抓取参数与body
api_params=values[api_method]['parameters'] if values[api_method].get('parameters') else {}
api_params_ref_path,api_params_ref_result_path,api_params_path=dispost_output_api_params(
api_params=api_params,api_params_type='path',api_params_ref_result=api_params_ref_result)
api_params_ref_body,api_params_ref_result_body,api_params_body=dispost_output_api_params(
api_params=api_params,api_params_type='body',api_params_ref_result=api_params_ref_result)
cls.api_params_path_list_descs.append(f"{api_params_ref_path}:->>{json.dumps(api_params_ref_result_path,ensure_ascii=False)}")
cls.api_params_path_list.append(json.dumps(api_params_path,ensure_ascii=False))
cls.api_params_body_list_descs.append(f"{api_params_ref_body}:->>{json.dumps(api_params_ref_result_body,ensure_ascii=False)}")
cls.api_params_body_list.append(json.dumps(api_params_body,ensure_ascii=False))
# 抓取响应
api_response=values[api_method]['responses'][cls.api_response_key] if values[api_method].get('responses') and \
values[api_method]['responses'].get(cls.api_response_key) else {}
api_response_ref,api_response_ref_result,api_response=dispost_output_api_params(
api_params=api_response,api_params_type='response',api_params_ref_result=api_response_ref_result)
if isinstance(api_response,list):
api_response=api_response[0]
cls.api_response_body_list_descs.append(f"{api_response_ref}:->>{json.dumps(api_response_ref_result,ensure_ascii=False)}")
cls.api_response_body_list.append(json.dumps(api_response,ensure_ascii=False))
# 拼接api_name
summary = values[api_method]['summary'] # 获取接口描述
cls.api_name_list.append(tags + '_' + summary)
@classmethod
def rm_old_file(cls):
'''删除旧数据,避免数据写入重复'''
if os.path.isfile(f'{os.path.join(cls.excel_path,cls.excle_name)}'):
print(f'删除文件:{os.path.join(cls.excel_path,cls.excle_name)}')
os.remove(f'{os.path.join(cls.excel_path,cls.excle_name)}') #删除文件
## shutil.rmtree('./') #删除文件夹及子目录下的所有文件
@classmethod
def write_data_to_excle(cls):
'''将api信息写入到excel'''
op_ex = operationExcle(excle_path=cls.excel_path, excle_name=cls.excle_name)
# 写入excel首行
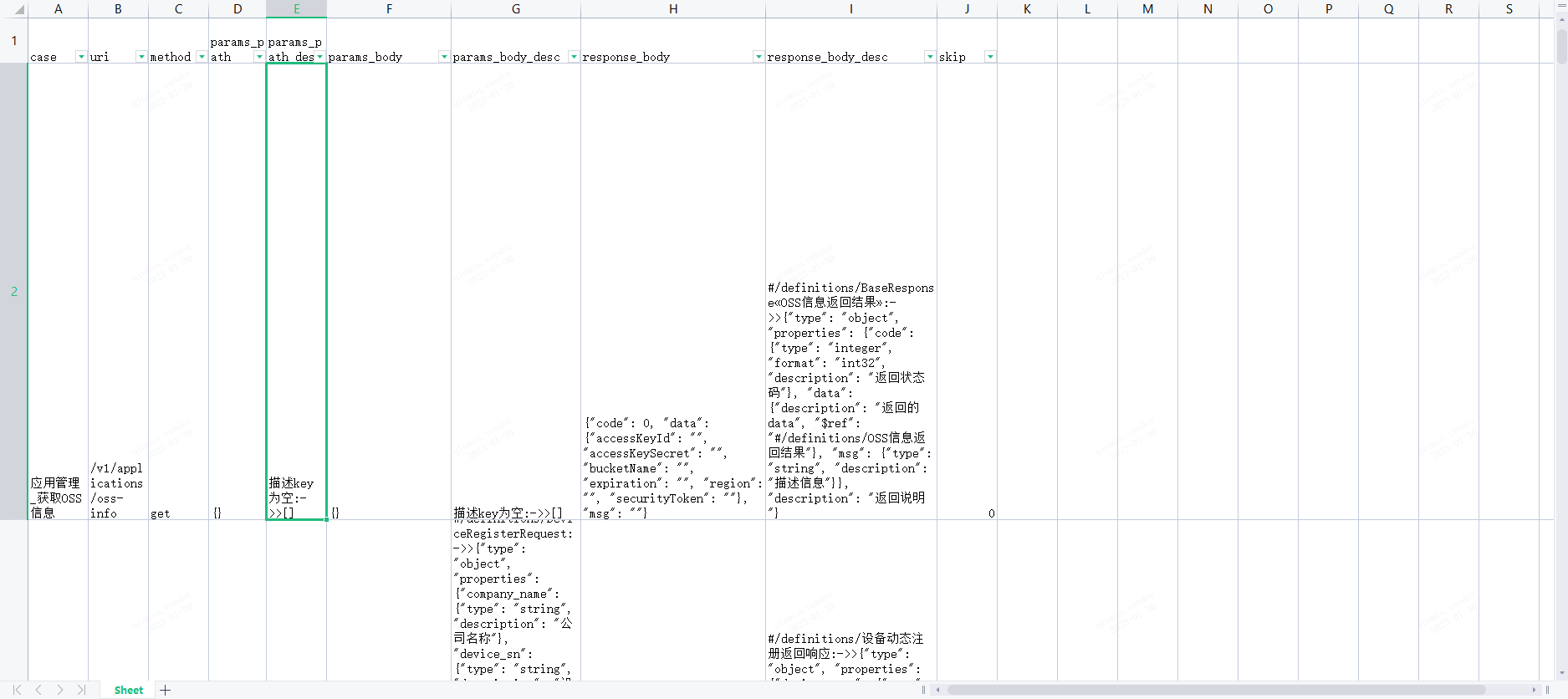
first_line=['case','uri','method','params_path','params_path_desc','params_body','params_body_desc','response_body','response_body_desc','skip']
op_ex.write_values(first_line)
# # 写入api信息到excle
for i in range(len(cls.api_uri_list)): # 将接口path循环写入第一列
api_infos=[cls.api_name_list[i],cls.api_uri_list[i],
cls.api_method_list[i],cls.api_params_path_list[i],
cls.api_params_path_list_descs[i],cls.api_params_body_list[i],
cls.api_params_body_list_descs[i],cls.api_response_body_list[i],
cls.api_response_body_list_descs[i],0]
op_ex.write_values(api_infos)
op_ex.save_workbook(cls.excle_name) # 保存文件
@classmethod
@exec_time_wrapper(round_num=10,module_obj=__file__,class_obj=sys._getframe().f_code.co_name,is_send_email=False)
def main(cls):
cls.get_info_info()
cls.rm_old_file()
cls.write_data_to_excle()
if __name__=="__main__":
sa=swaggerApiParse()
sa.main() 用到的依赖
operationExcle:基于openpyxl封装
# _*_ coding: UTF-8 _*_
"""
@project -> file : city-test -> rr
@Author : qinmin.vendor
@Date : 2023/1/29 19:44
@Desc : 自动生成接口测试用例:支持正交实验,等价类,边界值
"""
import demjson
import os
import openpyxl
# demjson:可以处理不规则的json字符串
# 常用的两个方法, 一个是 encode, 一个是 decode
# encode 将 Python 对象编码成 JSON 字符串
# decode 将已编码的 JSON 字符串解码为 Python 对象
class operationExcle(object):
def __init__(self, excle_path, excle_name):
self.excle_path=excle_path
self.excle_name=excle_name
if self.excle_path is None:
self.excle_path = os.path.join(os.path.dirname(__file__), '../config')
if self.excle_name is None:
self.excle_name='DataCase_ALL.xlsx'
self.file_address = os.path.join(self.excle_path, self.excle_name)
# # 类实例化时即完成对工作薄对象进行实例化,访问写入的数据不能立马生效的问题
if not os.path.exists(self.excle_path):
os.makedirs(self.excle_path)
if not os.path.exists(self.file_address):
# 创建工作薄
new_book = openpyxl.Workbook()
new_book.save(self.file_address)
self.workbook=openpyxl.load_workbook(self.file_address,data_only=True) #data_only=True,读取数据时保留exlce单元格格式
self.data=self.get_data()
self.__lines=self.get_lines()
def create_sheet(self, title=None, index=None,is_save=False):
'''创建sheet'''
self.workbook.create_sheet( title=title, index=index)
self.save_workbook()
if is_save:
self.save_workbook()
def rename_sheet_name(self,src_sheet_name,target_sheet_name,is_save=False):
'''
重命名sheet_name
Args:
src_sheet_name: 需要修改名称的sheet_name
target_sheet_name: 修改后的sheet_name
is_save: 是否保存
Returns:
'''
src_sheet_name_obj=self.get_data_for_sheet_name(sheet_name=src_sheet_name)
src_sheet_name_obj.title=target_sheet_name
if is_save:
self.save_workbook()
def copy_worksheet(self,src_sheet_name,target_sheet_name,is_save=False):
'''
复制工作簿内容
Args:
src_sheet_name: 需要被复制的sheet_name
target_sheet_name: 复制后的sheet_name
is_save: 是否保存
Returns:
'''
src_sheet_name_obj=self.get_data_for_sheet_name(sheet_name=src_sheet_name)
target_sheet_obj=self.workbook.copy_worksheet(src_sheet_name_obj)
target_sheet_obj.title=target_sheet_name
if is_save:
self.save_workbook()
def delete_sheet(self,sheet_name,is_save=False):
'''删除sheet'''
worksheet=self.get_data_for_sheet_name(sheet_name=sheet_name)
self.workbook.remove(worksheet)
if is_save:
self.save_workbook()
# 写入数据
def write_value(self, row, col, value,is_save=False):
'''写入excle数据row,col,value'''
# 设定单元格的值,三种方式
# sheet.cell(row=2, column=5).value = 99
# sheet.cell(row=3, column=5, value=100)
# ws['A4'] = 4 # write
data=self.data
data.cell(row=row,column=col).value=value
if is_save:
self.save_workbook()
def write_values(self,values:(list,tuple,dict),is_save=False):
'''
使用list、tuple、dict批量写入数据至excle
Args:
values:
Returns:
'''
data=self.data
data.append(values)
if is_save:
self.save_workbook()
# 基于ws删除一些行和一些列,注意没有备份,
# 并且最后没有保存,因为可能ws还有后续操作
# 必须记得最后还要保存。
def del_ws_rows(self, rows,is_save=False):
"""基于ws删除一"""
if not isinstance(rows,(list,tuple)):
rows=[rows]
rows = sorted(rows, reverse=True) # 确保大的行数首先删除
for row in rows: # rowd格式如:[1,3,5],表示要删除第1、3、5共三行。
self.data.delete_rows(row)
if is_save:
self.save_workbook()
def del_ws_cols(self, cols,is_save=False):
"""基于ws删除一些列"""
if not isinstance(cols,(list,tuple)):
cols=[cols]
cols = sorted(cols, reverse=True) # 确保大的列数首先删除
for col in cols: # cold格式如:[2,6,10],表示要删除第2、6、10共三列
self.data.delete_cols(col)
if is_save:
self.save_workbook()
#保存
def save_workbook(self,file_address=None):
if file_address is None:
file_address=self.file_address
else:
try:
file_address=os.path.join(self.excle_path,file_address)
except BaseException as error:
print("保存的文件路径还是不要乱来哦")
raise Exception(error)
# print(file_address)
self.workbook.save(file_address)
# 获取工作簿对象并返回,property将方法转换为属性
# 获取sheets的内容
def get_data(self,sheet_id=None):
data=self.workbook
if sheet_id is None:
sheet_id=0
else:
sheet_id=int(sheet_id)
# raise TypeError("sheet_id类型错误")
tables = data[(data.sheetnames[sheet_id])]
# 返回数据前先保存关闭
return tables
def get_all_sheet_name(self):
'''获取所有sheet_name'''
return self.workbook.sheetnames
def get_data_for_sheet_name(self,sheet_name=None):
sheet_names = self.get_all_sheet_name()
if not sheet_name:
sheet_name=sheet_names[0]
if sheet_name not in sheet_names:
raise Exception(f"{sheet_name}不在定义的列表范围内,预期:{sheet_names}")
tabels=self.workbook[sheet_name]
return tabels
# 获取单元格的行数
def get_lines(self,isRow=True):
tables = self.data
'''max_row:获取行数,max_column:获取列数
isRow:默认获取最大行数,flase:获取最大列数'''
if isRow:
lines=tables.max_row
else:
lines = tables.max_column
return lines
# 获取有效的行数,过滤一行数据全是None获取空格的情况
def get_valid_lines(self):
valid_lines=0
for i in range(1,self.__lines+1):
line_data=self.get_row_data(i)[0] #行数据第一个字段为空或者为空格,当做无效行
if line_data and str(line_data).strip():
valid_lines+=1
else:
break
self.__lines=valid_lines
return self.__lines
# 获取某一个单元格的内容
def get_cell_value(self, row, col):
cell_value=self.data.cell(row=row,column=col).value
# 也可以使用:cell_value=self.data['A1'].value
return cell_value
# 根据行列返回表单内容
# 根据对应的caseid找到对应行的内容
def get_row_data(self, case_id):
row_num = self.get_row_num(case_id)
rows_data = self.get_row_values(row_num)
return rows_data
# 根据对应的caseid找到相应的行号
def get_row_num(self, case_id):
'''用例起始行为2,所以这里需要指定now初始值为2'''
try:
num = 2
cols_data = self.get_cols_data(1)
cols_data=[int(i) for i in cols_data]
try:
case_id=int(case_id)
if case_id<=self.__lines:
if cols_data:
for col_data in cols_data:
if case_id == col_data:
return num
num = num + 1
else:
return None
else:
print('依赖caseId不能大于用例总行数')
return None
except TypeError as typeerror:
# print(typeerror)
return None
except (ValueError,TypeError) as e:
# print("excle 第一行内容不是int")
return case_id
# 根据行号找到该行内容
def get_row_values(self, row):
cols=self.get_lines(isRow=False)#获取最大列
rowdata=[]
for i in range(1,cols+1):
cellvalue=self.data.cell(row=row,column=i).value
rowdata.append(cellvalue)
return rowdata
# 获取某一列的内容
def get_cols_data(self, col=None):
rows = self.__lines#获取最大行
columndata=[]
for i in range(2,rows+1):
if col != None:
cellvalue = self.data.cell(row=i,column=col).value
else:
cellvalue=self.data.cell(row=i,column=1).value
columndata.append(cellvalue)
return columndata
class operationJson(object):
# 初始化文件
def __init__(self,json_path=None, file_path=None):
if json_path is None:
json_path = os.path.join(os.path.dirname(__file__), '../config')
else:
json_path=json_path
if file_path == None:
self.file_path = os.path.join(json_path,'Moudle_test.json')
else:
self.file_path = os.path.join(json_path,file_path)
self.dict={}#存放需要的数据
# self.data = self.read_data()
def read_data(self):
# with 语句适用于对资源进行访问的场合,确保不管使用过程中是否发生异常都会执行必要的“清理”操作,释放资源,
# 比如文件使用后自动关闭/线程中锁的自动获取和释放
# 读取json文件
with open(self.file_path, encoding='utf-8') as fp:
json_data=fp.read()
data = demjson.decode(json_data)
return data
# 根据关键字获取数据
def get_data(self, id=None):
data=self.read_data()
if id != None:
return data[id]
else:
print('id不存在,请检查id是否填写正确')
return None
# 写入json
def write_data(self, data):
with open(self.file_path, 'w') as fp:
fp.write(demjson.encode(data))
if __name__ == '__main__':
dict1 = {'crm_course_name':{"is_refund_audit":333,'this':100}}
# opym=OperationYaml()#'dependFieldInfo.yaml' #'dependKeyInfo.yaml'
# print(opym.readDataForKey('config'))
opx=operationExcle(excle_path='../other_scripts',excle_name='auto_genrate_api_case_allpairspy_params_field_detail.xlsx')
# print(opx.get_lines())
# print(opx.workbook_clear())
# print(opx.del_ws_cols(1))
# opx.create_sheet(title="888")
# opx.delete_sheet(sheet_name="应用管理_获取OSS信息")
# opx.rename_sheet_name(src_sheet_name='Sheet',target_sheet_name='666',is_save=True)
opx.copy_worksheet('Sheet','copy_test',is_save=True)
# print(opx.get_all_sheet_name())
# print(opx.get_data_for_sheet_name())
# print(opx.del_ws_rows(1,is_save=True))
# print(opx.del_ws_cols(1,is_save=True))
# print(opx.get_data_for_sheet_name())
# print(opx.get_data_for_sheet_name(sheet_name='business1'))
# print(opx.get_lines())
# print(opx.data.max_row)
# print(opx.data.max_column)
# print(opx.get_valid_lines())
# # print(opx.get_cols_data(7))
# print(opx.get_row_num(11)) requestMain:基于request封装
import json
import traceback
import requests
from utils.operation_logging import operationLogging
class requestMain(object):
# requests.packages.urilib3.disable_warnings() #禁用提醒
log=operationLogging()
# instance=None
# def __new__(cls, *args, **kwargs):
# if not cls.instance:
# cls.__session = requests.session()
# cls.request = None
# cls.__response = None
# cls.url = None
# cls.instance=super().__new__(cls)
# return cls.instance
def __init__(self):
self.__session = requests.session()
self.request = None
self.__response = None
self.url = None
@classmethod
def check_headers_files(cls,files,headers):
'''
检查headers与files的格式是否合规
'''
if not (files and len(files) <= 4 and isinstance(files, dict)):
files=None
if not headers:
headers=None
return files,headers
def get_main(self, url, data, headers, params=None, files=None,cookies=None): # 封装get请求
# verify:验证——(可选)要么是布尔型,在这种情况下,它控制我们是否验证服务器的TLS证书或字符串,在这种情况下,它必须是通往CA捆绑包的路径。默认值为True
# res=self.__session.get(uri=uri,params=data,headers=headers,verify=false)
# get请求请求参数尽量不要编码,防止会有一些错误,这里手动处理一下错误
try:
res = self.__session.get(url=url, params=params,data=data, headers=headers, files=files, verify=False,cookies=cookies)
return res
except:
self.log.log_main('error', False, None, f"get请求发生错误:{traceback.format_exc()}")
def post_main(self,url, data, headers, params=None, files=None,cookies=None): # 封装post请求
try:
res = self.__session.post(url=url, params=params,data=data,headers=headers, files=files, verify=False,cookies=cookies)
return res
except:
self.log.log_main('error', False, None, f"post请求发生错误:{traceback.format_exc()}")
def put_main(self,url, data, headers, params=None, files=None,cookies=None): # 封装put请求
try:
res = self.__session.put(url=url, params=params,data=data, headers=headers, files=files, verify=False,cookies=cookies)
return res
except:
self.log.log_main('error', False, None, f"put请求发生错误:{traceback.format_exc()}")
def delete_main(self,url, data, headers, params=None, files=None,cookies=None): # 封装put请求
try:
res = self.__session.delete(url=url, params=params,data=data, headers=headers, files=files, verify=False,cookies=cookies)
return res
except:
self.log.log_main('error', False, None, f"delete请求发生错误:{traceback.format_exc()}")
def run_main(self, host,uri, method,params=None,body=None, headers=None, files=None,cookies=None, res_format='json',is_log_out=False): # 封装主请求
'''参数1:请求方式,参数2:请求data,参数3:请求信息头,参数4:返回的数据格式'''
# 相关源码:
# ''' :param files: (optional) Dictionary of ``'name': file-like-objects`` (or ``{'name': file-tuple}``) for multipart encoding upload.
# ``file-tuple`` can be a 2-tuple ``('filename', fileobj)``, 3-tuple ``('filename', fileobj, 'content_type')``
# or a 4-tuple ``('filename', fileobj, 'content_type', custom_headers)``, where ``'content-type'`` is a string
# defining the content type of the given file and ``custom_headers`` a dict-like object containing additional headers
# to add for the file. '''
# files参数示例:
# files={'file': ('git.docx', open('C:/Users/Acer/Downloads/git.docx', 'rb'))}
if not (host.startswith('http://') or host.startswith('https://')) :
self.log.log_main('error', False, None, f"host:{host},格式错误")
raise Exception(f"host:{host},格式错误")
if host.endswith('/') and uri.startswith('/'):
host=host[:-1]
if not (host.endswith('/') or uri.startswith('/')) :
uri='/'+uri
if str(body).startswith("{") and str(body).endswith("}") and isinstance(body,dict):
body=json.dumps(body)
files,headers=self.check_headers_files(files=files,headers=headers)
self.url=host+uri
if method.lower() == 'get' :
res = self.get_main(url=self.url, params=params, data=body, headers=headers,files=files,cookies=cookies)
elif method.lower() == 'post' :
res = self.post_main(url=self.url, params=params, data=body, headers=headers, files=files,cookies=cookies)
elif method.lower() == 'put' :
res = self.put_main(url=self.url, params=params, data=body, headers=headers, files=files,cookies=cookies)
elif method.lower() == 'delete' :
res = self.delete_main(url=self.url, params=params, data=body, headers=headers, files=files,cookies=cookies)
else:
self.log.log_main('error',False,None,f"不支持的请求方式:{method}")
# res=None
raise Exception("暂不支持的请求方式")
self.request=res
# self.log.log_main('info',False,None,f"request:{self.request}")
try:
if res_format.lower() == 'json' : # 以json格式返回数据
'''ensure_ascii:处理json编码问题(中文乱码),separators:消除json中的所有空格'''
response = res.json()
elif res_format.lower() in ('text','str'): # 以文本格式返回数据
response = res.text
elif res_format.lower() == 'content' : # 以二进制形式返回响应数据
response = res.content
else: # 以json格式返回数据
response = res.json()
self.__response=response
return response
except BaseException as e:
if is_log_out:
self.log.log_main('error', False, None, traceback.format_exc())
return res.text
finally:
if is_log_out:
self.log.log_main('info', False, None, f'请求url:{self.url}')
self.log.log_main('info', False, None, f'请求method:{method}')
self.log.log_main('info', False, None, f'请求body:{body}')
self.log.log_main('info', False, None, f'请求headers:{headers}')
self.log.log_main('info', False, None, f'请求响应:{self.__response}')
self.log.log_main('info', False, None, f'请求响应code:{self.request.status_code}')
def get_response_with_status_code(self):
return int(self.request.status_code)
def get_response(self):
return self.__response
if __name__ == '__main__':
r = requestMain() dataUtil:个人封装的一些常用的数据处理的方法
import traceback
from utils.operation_logging import operationLogging
from jsonpath_rw_ext import parse
from utils.time_utils import timeUtil
class dataUtil(timeUtil):
log=operationLogging()
# 返回依赖数据
def depend_data_parse(self,dependkey,response_data,index='one'):
__dict={}#存放字典
'''处理依赖'''
if dependkey:
# 匹配字典key
depend_data_index = dependkey.rfind('.')
depend_data_str = dependkey[depend_data_index + 1:]
try:
math_value = self.json_path_parse_public(json_path=dependkey,json_obj=response_data)
if math_value:
if index=='one':
math_value=math_value[0]
__dict[depend_data_str]=math_value
return __dict
else:
return None
except IndexError as indexerror:
return None
else:
return None
# 根据jsonpath表达式获取json对象公共方法,部分功能还需要测试
def json_path_parse_public(self,json_path,json_obj,get_index:bool=False):
if json_path:
# 定义要获取的key
# 定义响应数据,key从响应数据里获取
# print(madle)
# math.value返回的是一个list,可以使用索引访问特定的值jsonpath_rw的作用就相当于从json里面提取响应的字段值
try:
json_exe = parse(json_path)
madle = json_exe.find(json_obj)
math_value = [i.value for i in madle]
if get_index:
return math_value[0]#返回匹配结果第0个元素
return math_value
except IndexError :
self.log.log_main('info',False,None,f"json_obj:{json_obj}提取失败,json_path:{json_path}")
return []
except Exception :
self.log.log_main('error', False, None, f"json_obj:{json_obj}提取失败,json_path:{json_path},具体错误,{traceback.format_exc()}")
return []
else:
return []
if __name__ == "__main__":
du=dataUtil()
print(du.json_path_parse_public(json_path="$.definitions.Page«object»", json_obj={})) operationLogging:基于loguru封装
# _*_ coding: UTF-8 _*_
"""
@project -> file : city-test -> rr
@Author : qinmin.vendor
@Date : 2023/1/29 19:44
@Desc :
"""
import os
from loguru import logger
# 发生Error日志时,发邮件进行警报
from utils.send_email import sendEmail
from tabulate import tabulate
class operationLogging(object):
__email = sendEmail()
__instance=None
__email_user_list=None
__log_path=None
email_sub='日志告警' #邮件标题
def __new__(cls, *args, **kwargs):
if not cls.__instance:
cls.__log_path = cls.log_path()
cls.__instance=object.__new__(cls)
return cls.__instance
@classmethod
def log_path(self):
"""Get log directory"""
path = os.path.join(os.path.dirname(os.path.dirname(os.path.abspath(__file__))), "log")
if not os.path.exists(path):
os.mkdir(path)
return path
@classmethod
def json_log_msg(cls,*log_msg):
try:
if not isinstance(log_msg,(tuple,list,set)):
return log_msg
log_msg=','.join(log_msg)
except:
log_msg=','.join([str(i) for i in log_msg])
finally:
return log_msg
@classmethod
def log_main(cls,log_level,is_send_email=False,*log_msg):
'''
Args:
log_level:
*log_msg:
Returns:
'''
# 去除控制台日志
# logger.remove(handler_id=None)
log_msg=cls.json_log_msg(*log_msg)
__log_name=os.path.join(cls.__log_path,f"{log_level}"+"_{date}.log")
logger_conf = {
"format": '{time:YYYY-MM-DD HH:mm:ss} | {level} | {module}:{function}:{line} process_id:{process} thread_id:{thread}, log_content:{message}',
# 配置按大小滚动:rotation, 压缩日志:compression, 多进程安全:enqueue=True
"rotation":"10 MB","compression":"zip","enqueue":True,
# 错误堆栈
"backtrace" : True, "diagnose" : True,
'encoding':'utf-8',
# 'level':'INFO', #级别等于或高于info的日志才会记录日志到文件中
}
# 添加log_headel,并记录对应的线程
log_handel=logger.add(__log_name,**logger_conf)
if log_level not in ('debug','info','warning','error'):
log_level='info'
if log_level=='debug':
logger.debug(log_msg)
elif log_level=='info':
logger.info(log_msg)
elif log_level=='warning':
logger.warning(log_msg)
else:
logger.error(log_msg)
if is_send_email:
cls.__email.send_msg(sub=cls.email_sub,msg=log_msg,user_list=cls.__email_user_list)
# 移除handel,避免重复打印
logger.remove(log_handel)
@classmethod
def log_main_table(cls,log_level,is_send_email=False,tabel_header=[],tabel_data=[],tablefmt='grid'):
'''打印表格形式的日志,配合tabulate使用:
https://blog.csdn.net/qq_43901693/article/details/104920856
tablefmt支持: 'plain', 'simple', 'grid', 'pipe', 'orgtbl', 'rst', 'mediawiki',
'latex', 'latex_raw', 'latex_booktabs', 'latex_longtable' and tsv 、jira、html'''
def convert_to_container(obj):
if not isinstance(obj,(list,tuple,set)):
return [obj]
return obj
tabel_header = convert_to_container(tabel_header)
tabel_data=convert_to_container(tabel_data)
log_msg=tabulate(tabular_data=tabel_data,headers=tabel_header,tablefmt=tablefmt)
log_msg=f'\ntabel_format:{tablefmt}\n{log_msg}'
cls.log_main(log_level,is_send_email,log_msg)
if __name__=="__main__":
op_log=operationLogging()
# op_log.log_main('info',True,'1','2','3',(1,2,34))
# op_log.log_main('debug',True,'1','2','3',(1,2,34))
op_log.log_main_table(log_level='info',is_send_email=False,tabel_header=['name','age'],tabel_data=[('xiaoming',12),('xiaobai',13)],tablefmt='html') 最终效果: