自己动手实现 HashMap(Python字典),彻底系统的学习哈希表(上篇)——不看血亏!!!
HashMap(Python字典)设计原理与实现(上篇)——哈希表的原理
在此前的四篇长文当中我们已经实现了我们自己的
ArrayListLinkedListArrayListLinkedListJDKHashMapHashMapJDKHashMap如果有公式渲染不了,可查看这篇内容相同且可渲染公式的文章
HashMap初识
如果你使用过
HashMapHashMap键值(key, value) public static void main(String[] args) {
HashMap<String, Integer> map = new HashMap<>();
map.put("学生A", 60);
map.put("学生B", 70);
map.put("学生C", 20);
map.put("学生D", 85);
map.put("学生E", 99);
System.out.println("学生B的分数是:" + map.get("学生B"));
} 我们知道
HashMapget函数O(1)我们知道在计算机当中一个最基本也是唯一的,能够实现常数级别的查询的类型就是数组,数组的查询时间复杂度为
O(1)6 String[] strs = new String[10];
strs[6] = "一无是处的研究僧";
System.out.println(strs[6]); 因此我们要想实现
HashMapO(1)HashMapJDKHashMap整体设计
我们实现的
HashMap键(key)值(value)因此我们可以有一个这样的设计,我们可以根据数据的
键值哈希函数哈希值键值成绩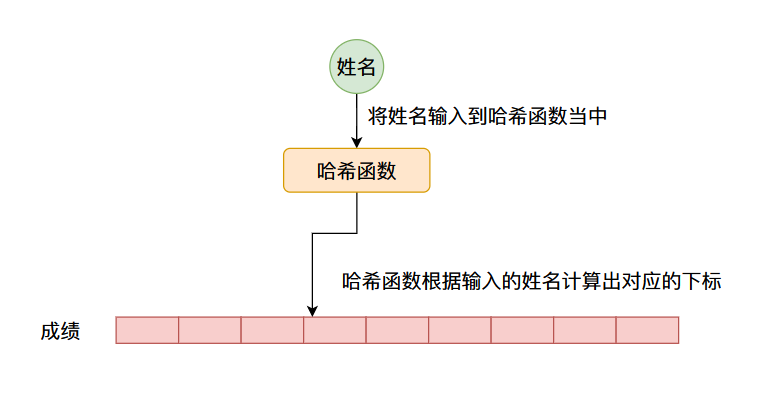
但是像这种哈希函数计算出来的数值一般是没有范围的,因此我们通常通过哈希函数计算出来的数值通常会经过一个求余数操作(
%186%16=10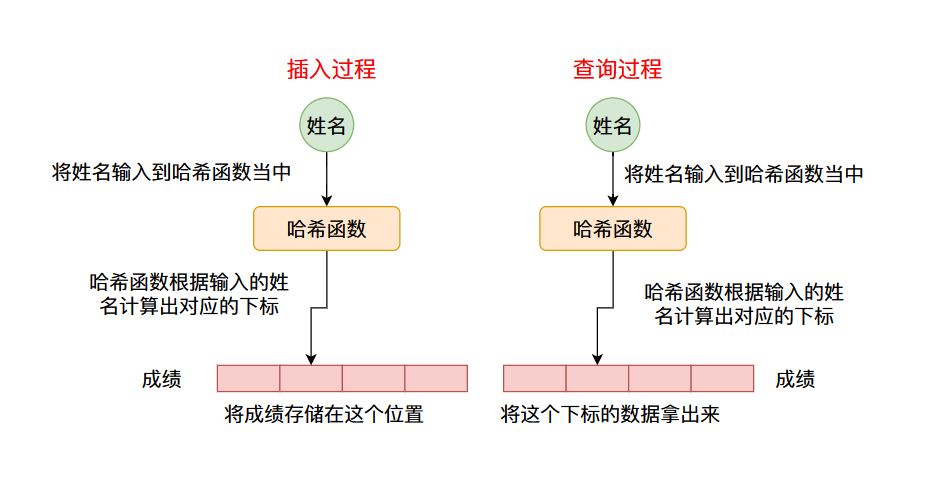
如何设计一个哈希函数?
首先我们需要了解一个知识,那就是在计算机世界当中我们所含有的两种最基本的数据类型就是,整型(
shortintlongString整型的哈希函数
对于整型数据,他本来就是一个数值,因此我们可以直接将这个值返回作为他的哈希值,而
JDKJDK /**
* Returns a hash code for a {@code int} value; compatible with
* {@code Integer.hashCode()}.
*
* @param value the value to hash
* @since 1.8
*
* @return a hash code value for a {@code int} value.
*/
public static int hashCode(int value) {
return value;
} 字符串的哈希函数
我们知道字符串底层存储的还是用整型数据存储的,比说说字符串
hello world['h', 'e', 'l', 'l', 'o' , 'w', 'o', 'r', 'l', 'd']哈希冲突JDK public int hashCode() {
// hash 是 String 类当中一个私有的 int 变量,主要作用即存储计算出来的哈希值
// 避免哈希值重复计算 节约时间
int h = hash; // 如果是第一次调用 hashCode 这个函数 hash 的值为0,也就是说 h 值为 0
// value 就是存储字符的字符数组
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
// 更新 hash 的值
hash = h;
}
return h;
} 上面的计算
hashCode- 其中
,表示存储字符串的字符数组s -
表示字符数组当中字符的个数n
\]
自定义类型的哈希函数
比如我们自己定义了一个学生类,我们改设计他的哈希函数,并且计算他的哈希值呢?
class Student {
String name;
int grade;
} 我们可以根据上面提到的两种哈希函数,仿照他们的设计,设计我们自己的哈希函数,比如像下面这样。
class Student {
String name;
int grade;
// 我们自己要实现的哈希函数
@Override
public int hashCode() {
return name.hashCode() * 31 + grade;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return grade == student.grade &&
Objects.equals(name, student.name);
}
} 事实上
JDK // 下面这个函数是我们自己设计的类 Student 的哈希函数
@Override
public int hashCode() {
return Objects.hash(name, grade);
}
// 下面这个函数为 Objects.hash 函数
public static int hash(Object... values) {
return Arrays.hashCode(values);
}
// 下面这个函数为 Arrays.hashCode 函数
public static int hashCode(Object a[]) {
if (a == null)
return 0;
int result = 1;
for (Object element : a)
result = 31 * result + (element == null ? 0 : element.hashCode());
return result;
}
JDK集合类型的哈希函数
其实集合类型的哈希函数也可以像字符串那样设计哈希函数,我们来看一下
JDK public int hashCode() {
int hashCode = 1;
// 遍历集合当中的对象,进行哈希值的计算
for (E e : this)
hashCode = 31*hashCode + (e==null ? 0 : e.hashCode());
return hashCode;
} 上述代码也可以用之前的公式来表示,其中
s[i]i
\]
哈希冲突
因为我们用的最终的数组的下标是通过哈希值取余数得到的,那么就有可能产生冲突。比如说我们的数组长度为
10828108开放地址法(再散列法)
线性探测再散列
假设我们的哈希函数为
Hmkey
\]
当我们有哈希冲突的时候,我们计算下标的方法变为:
\]
当我们第一次冲突的时候 \(d_1 = 1\) ,如果重新进行计算仍然冲突那么 \(d_2 = 2\) ......
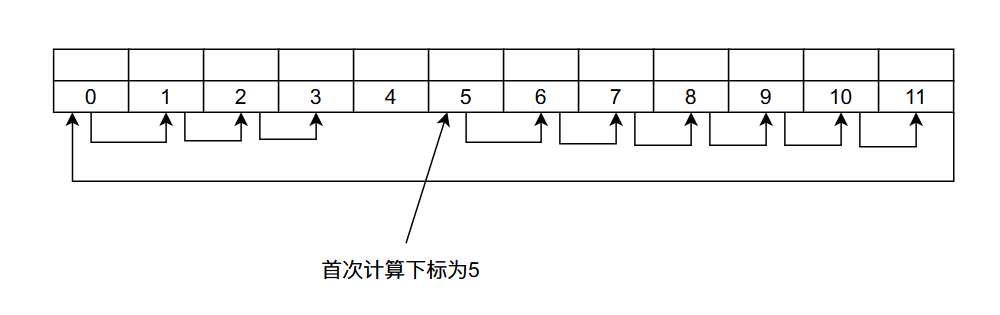
比如在上图当中我们首次计算的哈希值 \(H(key) = 5\) 的结果等于5,如果有哈希冲突,那么下次计算出来的哈希值为 \((H(key) + 1) \% 12 = 6\) ,如果还是冲突那么计算出来的哈希值为 \((H(key) + 2) \% 12 = 7\) ......,直到找到一个空位置。谈到这里你可能会问,万一都满了呢?我们在下一小节再谈这个问题。
二次探测再散列
\]
这个散列方法和线性探测散列差不多,只不过 \(d_i\) 的值变化情况不一样而已,大家可以参考线性探测进行分析,这个方法可以往数组的两个方法走,因为前面有一个而线性探测只能往数组的一个方向走。此外这个方法走的距离比线性探测更大,因此可能可以在更小的冲突次数当中找到一个
空位置伪随机数再散列
\]
这个方式的大致策略和前面差不多,只不过 \(d_i\) 上稍微有所差异。
再哈希法
我们可以准备多个哈希函数,当使用一个哈希函数产生冲突的时候,我们可以换一个哈希函数,希望通过不同的哈希函数得到不同的哈希值,以解决哈希冲突的问题。
链地址法
这个方法是目前使用比较多的方法,当产生哈希冲突的时候,数据用一个链表将冲突的数据链接起来,比如像下面这样:
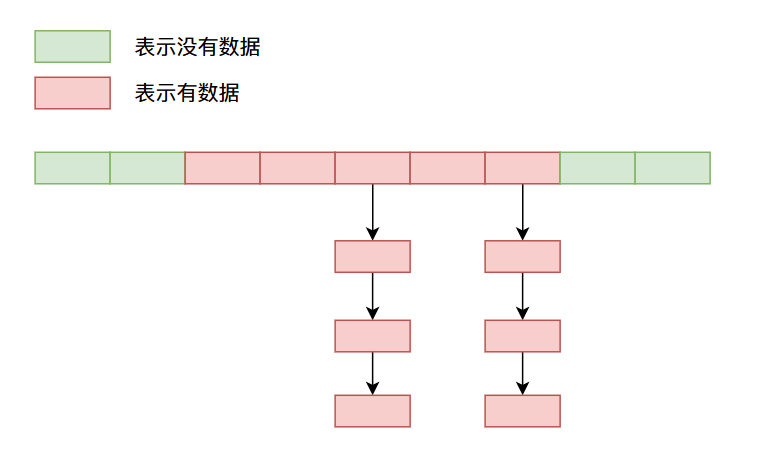
以上就是一些常见的解决哈希冲突的方法,因为都是文字说明没有代码,你可能稍微有些难以理解,比如说我通过上面的方法存储数据,那么我之后怎么拿到我存进去的数据呢?好像放进去就拿不出来了呀????????????!没事儿,这些疑问我们在
下篇扩容
在上面的文章当中我们并没有谈到当数组满了之后怎么办。很简单嘛,我可以使用一个变量记录数组当中已经使用了的空间,如果全部使用过了,我们就进行扩容,扩大我们的数组就可以了嘛!然后将原数组当中的数据重新进行哈希存放到新数组当中即可!因为我们在计算存储下标的时候需要对数组长度进行取余,而当我们申请新数组的时候数组长度已经发生变化了,因此需要重新对数据进行哈希操作。这里面仍然有很多需要考虑的细节问题,比如说负载因子,这些问题我们在
下篇总结
在本篇文章当中,我们主要谈到了如何去设计一个可以使用的哈希表,同时介绍了我们改如何设计一个哈希函数,最终谈到了解决哈希冲突和数组满了的问题!!!
-
整体的设计结构。HashMap -
设计一个好的哈希函数。
- 整型数据的哈希函数。
- 字符串的哈希函数。
- 自定义类型的哈希函数。
- 集合的哈希函数。
-
解决哈希冲突的办法。
- 开放地址法
- 线性探测
- 二次探测
- 随机数探测
- 再哈希法
- 链地址地址法
- 开放地址法
-
扩容方法
以上就是本篇文章的所有内容了,我们将在
下篇MyHashMap更多精彩内容合集,可访问:https://github.com/Chang-LeHung/CSCore
关注公众号:一无是处的研究僧,了解更多计算机知识!!!