Redis常见问题
一.Redis的持久化方式?
RDB:定时对数据内存做快照存储
AOF:记录执行的命令
默认开启RDB,AOF需手动设置开启使用;实际的应用中,采取RDB+AOF结合使用
二者区别
| RDB | AOF | |
|---|---|---|
| 数据完整性 | 低(两次备份有丢失数据的风险) | 高 |
| 宕机恢复速度 | 快(数据) | 慢(记录的命令) |
| 数据优先级 | 低(数据完整性低于AOF) | 高 |
| 文件大小 | 小(文件可以压缩,并且记录值) | 大 |
| 内存占用 | 大量CPU和内存消耗 | AOF主要占用磁盘IO资源,在重写时,会占用CPU和内存消耗 |
| 应用场景 | 追求更快的启动速度使用RDB | 追求数据的安全性 |
触发条件
RDB触发机制有三种,分别是:save触发、bgsave触发和自动触发
- bgsave触发
具体流程是Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短。bgsave命令也是Redis内部RDB操作的默认方式。
- 自动触发
配置:save second changes
作用:满足限定时间范围内key的变化数量达到指定数量即进行持久化
参数:second:监控时间范围,changes:监控key的变化量
位置:在conf文件中进行配置
范例: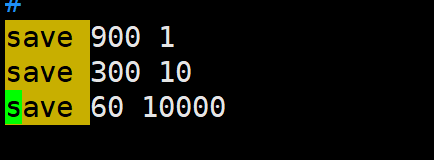
配置的含义:
900秒之内至少一次写操作、300秒之内至少发生10次写操作、60秒之内发生至少10000次写操作;只要满足任一条件,均会触发bgsave
AOF触发的条件有三种可以设置 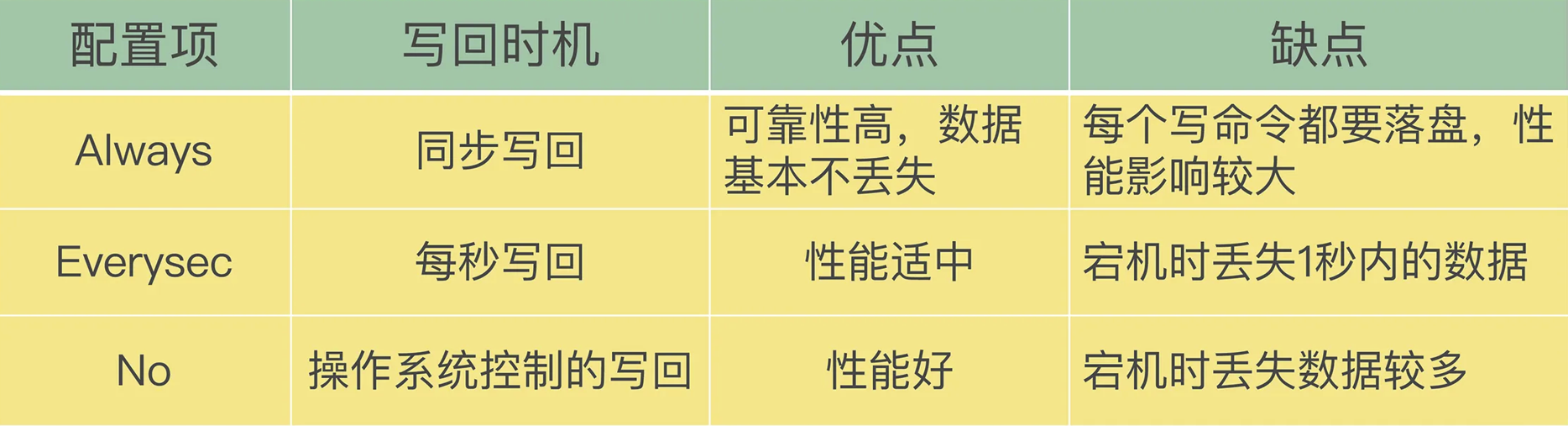
二.Redis为什么这么快?
- 单线程,避免了多线程的频繁切换开销
- 内存操作
- IO多路复用
- 跳跃表
三.Redis的过期删除策略和内存淘汰机制
1.过期删除策略
定时: redis中存入一个带有过期时间的key时,会为这个key生成一个专属的定时器,用来监视这个key的过期时间,当过期时间达到后,立即进行删除;优点是redis中的数据可以保持为最新的数据,但缺点是每个带有过期时间的key都会分配一个定时器,对CPU和内存占用消耗是很大的;
定期: redis每隔100ms会抽取一部分key检验其过期时间,达到后将其删除;但是可能有些过期了的key始终抽取不到,导致内存占用问题,于是定期删除策略都和惰性删除策略结合使用;
惰性: 当使用到某个key是,redis会先检验key的过期时间,时间达到进行删除,弊端是某个不经常使用的key清楚不掉,占用内存;
在使用redis的过期删除策略时,采取的是定期+惰性,还会使用redis的内存淘汰机制!
2.内存淘汰机制
- novecation:当内存不足以容纳新数据时,抛出异常;
- allkeys-lru:当内存不足以容纳新数据时,使用lru算法,从所有的key中找出最不常使用的key进行删除;
- allkeys-random :当内存不足以容纳新数据时,随机抽取某个key进行删除;
- volatile-lru:当内存不足以容纳新数据时,使用lru算法,从已设置过期时间的key中,找出最近不常使用的key进行删除;
- volatile-random:当内存不足以容纳新数据时,从已设置过期时间的key中,随机抽取某个key进行删除;
- volatile-ttl:删除到期时间最早的key;
四.Redis的五种数据类型
List、String、Set、ZSet、Hash
详细命令可参考redis中文网:https://www.redis.net.cn/
五.雪崩、击穿、穿透
1.雪崩
如果在某一时刻缓存集中失效,或者缓存系统出现故障,所有的并发流量就会直接到达数据库。数据存储层的调用量就会暴增,用不了多长时间,数据库就会被大流量压垮,这种级联式的服务故障,就叫作缓存雪崩。
解决方案
- 解决缓存雪崩问题最常用的一种方案就是保证Redis的高可用,将Redis缓存部署成高可用集群(必要时候做成异地多活),可以有效的防止缓存雪崩问题的发生。
- 为了缓解大并发流量,我们也可以使用限流降级的方式防止缓存雪崩。例如,在缓存失效后,通过加锁或者使用队列来控制读数据库写缓存的线程数量。具体点就是设置某些Key只允许一个线程查询数据和写缓存,其他线程等待。则能够有效的缓解大并发流量对数据库打来的巨大冲击。
- 另外,我们也可以通过数据预热的方式将可能大量访问的数据加载到缓存,在即将发生大并发访问的时候,提前手动触发加载不同的数据到缓存中,并为数据设置不同的过期时间,让缓存失效的时间点尽量均匀,不至于在同一时刻全部失效。
2.击穿
缓存中的数据在某个时刻批量过期,导致大部分用户的请求都会直接落在数据库上,这种现象就叫作缓存击穿。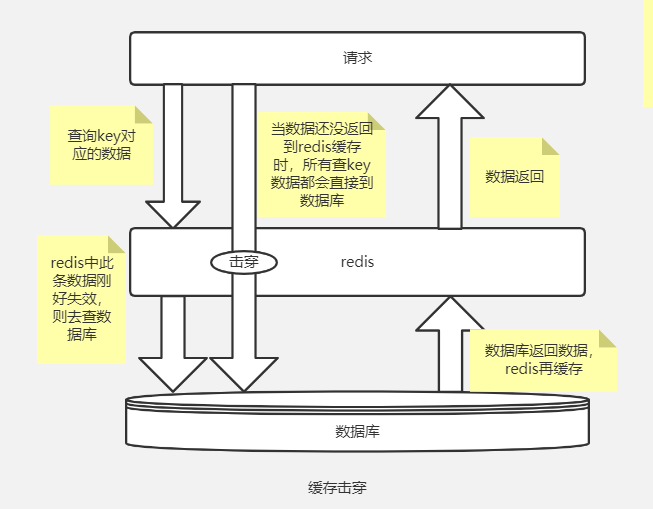
解决方案
- 对于比较热点的数据,我们可以在缓存中设置这些数据永不过期;也可以在访问数据的时候,在缓存中更新这些数据的过期时间;如果是批量入库的缓存项,我们可以为这些缓存项分配比较合理的过期时间,避免同一时刻失效。
- 还有一种解决方案就是:使用分布式锁,保证对于每个Key同时只有一个线程去查询后端的服务,某个线程在查询后端服务的同时,其他线程没有获得分布式锁的权限,需要进行等待。不过在高并发场景下,这种解决方案对于分布式锁的访问压力比较大。
3.穿透
在查询某个Key对应的数据时,Redis缓存中没有相应的数据,则直接到数据库中查询。数据库中也不存在要查询的数据,则数据库会返回空,而Redis也不会缓存这个空结果。导致查询每次都会请求到数据库;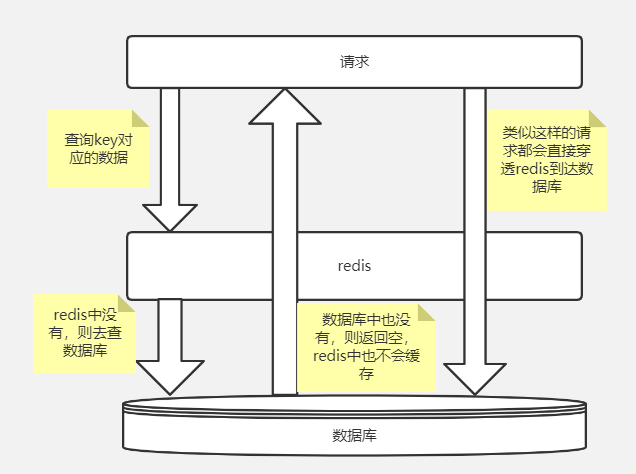
解决方案
- 当进行查询时,发现key不存在,则为其设置个空值并设置合理的过期时间,减少数据库的压力
- 布隆过滤器:设置布隆过滤器,相当于redis的网关,会对redis的key进行三次hash计算,得到的结果都为1的话证明redis中存在对应的key,才会进入redis中,key有值返回数据,无值访问数据库,得到结果再存储到redis中;